圖片來源:
Google Deepmind
Alphabet旗下的AI子公司DeepMind正在研究如何幫「生成式影片」生成背景聲音,利用影片至聲音(video-to-audio,V2A)技術來替這些原本無聲的影片加上應有的對話、音效或配樂。
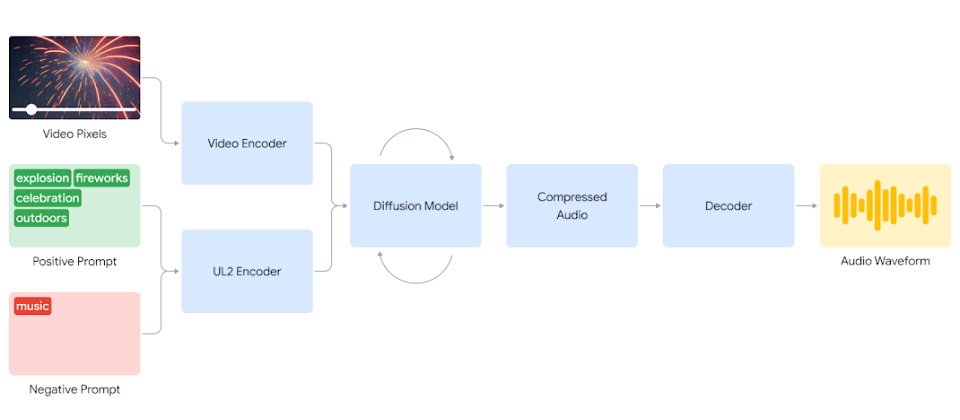
目前DeepMind的V2A技術並不是直接餵入影片就能生成聲音,而是結合了自然語言的提示以幫螢幕上的畫面配音,相容於諸如Veo等影片生成模型,並支援包括檔案、無聲電影等影片內容。
當使用者輸入音訊及文字提示時,V2A便可生成與影片同步的音訊波形。它會先將所輸入的影片及提示輸入數位化,再利用擴散模型反覆運算,最終生成一個壓縮的聲音文件,再由系統將其解碼,藉以產生與影片畫面高度協調的背景聲音,完全不需要手動對齊影片及所生成的聲音。
在V2A技術的展示影片中,DeepMind團隊輸入了一個在黑暗中行走的影片畫面,再提供「電影、恐怖片、音樂、緊張、混凝土上的腳步聲」等文字提示,V2A就能生成恐怖片的背景音樂;還能幫無聲的擊鼓畫面配樂;或是要求它生成搭配畫面的海洋音樂。
此外,V2A可替任何影片生成無限數量的音軌,還能選擇正向或反向的文字提示,以要求所生成的聲音更貼近或遠離某些情境。
透過對影片、聲音及註譯的訓練,V2A現階段已能連結特定的音訊與不同的視覺場景,亦能對註釋或轉錄文字中的資訊作出反應;DeepMind也正在改善V2A生成結果中關於說話的口型同步能力。
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06

2026-02-09
")
2026-02-09

")
Advertisement