Apple
重點新聞(1004~1010)
蘋果 UI螢幕 MM1.5
UI螢幕互動成多模態模型新戰場,蘋果揭露新研究成果
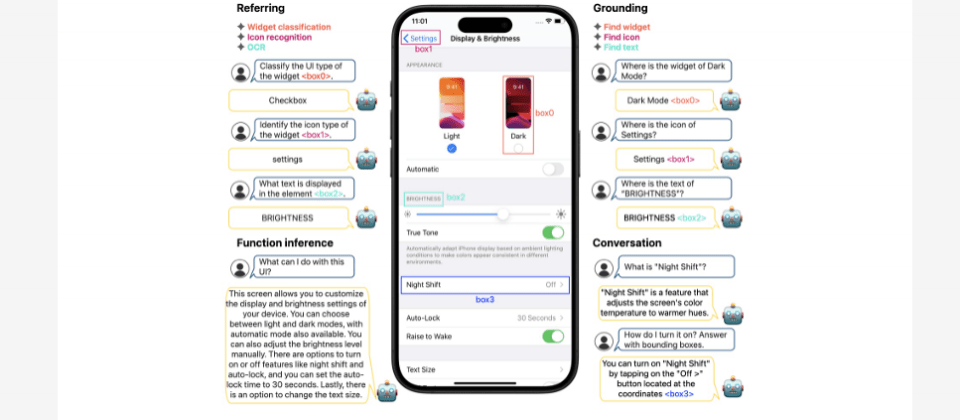
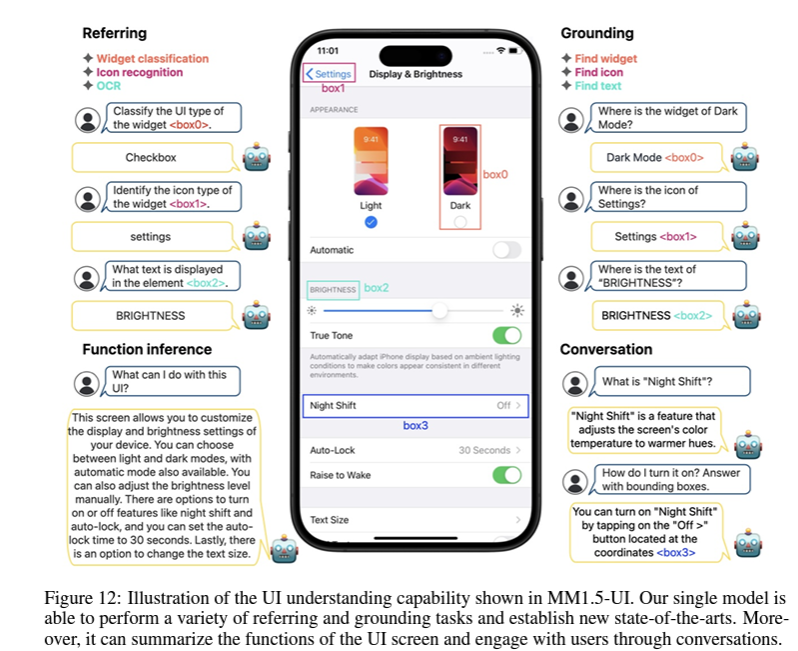
蘋果發表多模態大型語言模型MM1.5系列模型,透過訓練階段精挑細選的資料混合方法,提高了模型對多文字圖像理解、視覺引用和定位(Grounding)以及多圖像推理的能力。該模型架構以前一代模型MM1架構為基礎,訓練原則也延續以資料為中心,探索在不同訓練周期中,不同的混合資料方法對模型表現的影響。
舉例來說,團隊在MM1.5持續預訓練階段,導入高品質的OCR資料和合成圖說,可大幅提升模型對多文字圖像的理解力。又或是在監督式微調階段,對不同類型資料的影響進行分析,找出最佳的視覺指令微調資料混合方法。MM1.5系列模型的大小從10億參數到300億參數不等,採用不同類型架構,如密集模型和專家混合(MoE)模型。團隊表示,即使是10億參數和30億參數的小規模模型,透過精細的資料管理和訓練策略,也能發揮強大表現。
特別的是,蘋果還同時打造了專門處理影片理解的模型MM1.5-Video,以及專門理解行動裝置UI(如iPhone螢幕)的MM1.5-UI模型。他們強調,將多模態模型應用於行動裝置螢幕互動,比如代表使用者與裝置互動或與使用者一起理解UI,是一項有潛力的應用場景,可提高使用效率和生產力。而MM1.5-UI單一模型,就能執行多種視覺引用和定位任務,還能摘要UI螢幕上的功能,甚至透過與使用者對話來互動。雖然模型拿下SOTA表現,團隊將繼續優化模型,比如透過多模態融合方法,將文字、圖片和使用者互動資料融合,設計出更複雜的網路架構,來讓模型參考多種資料來源、提高對行動裝置UI的理解。(詳全文)
諾貝爾物理獎 神經網路 機器學習
兩位機器學習先鋒獲得諾貝爾物理獎
瑞典皇家科學院日前宣布2024年諾貝爾物理獎得主,包括現年91歲的John Hopfield和76歲的Geoffrey Hinton,來表彰他們從1980年代開始,就以人工神經網路打下機器學習基礎。瑞典皇家科學院表示,人們談論的AI,通常指以人工神經網路為基礎的機器學習,也就是受大腦結構啟發,在人工神經網路中,大腦的神經元由不同值的節點來表現,節點之間透過連結來相互影響,如同大腦中的突觸,並可調整連結的強弱。
其中,Hopfield是著名的理論物理學家及神經科學家,曾建立開創性的Hopfield網路,以一種特殊的方式來儲存並重建模式(Pattern)。簡單地說,該網路是透過物理學中,能量最小化的過程來進行自我組織與學習,成為之後許多深度學習研究的靈感來源。Hinton則以Hopfield網路為基礎,利用統計物理學工具,以不同方式建立了Boltzmann機器網路,能自動學習、辨識資料中的特徵,比如分類圖片,此舉推動了機器學習的重大發展。(詳全文)
影片生成 Meta 配樂
Meta預告影片生成AI模型Movie Gen
Meta最近揭露AI影片生成模型Meta Movie Gen,可生成高品質的圖片和影片、音效或配樂,效能比OpenAI Sora等先進模型要好。不過,Movie Gen還在開發中,Meta在官方部落格稱其為AI媒體研究的重大突破,具多模態能力,可處理圖片、影像和聲音,開發者輸入文字提示即可產生影片和音訊、編輯現有影片,或是將圖片轉化為影片,克服了生成影片常出現的物件扭曲/模糊、動作不自然、或罕見動作不完整等問題。
早在2022年,Meta就發布第一代多模態AI模型Make-A-Scene,能產製影音、圖片和3D動畫,第二代則是基於擴散模型的Llama Image基礎模型,提供更高影音品質及圖片編輯功能。Movie Gen屬於第三代,融合所有模態,是以經授權或公開可用的資料集訓練而成的300億參數Transformer模型。該模型有4個版本,包括影片生成、個人化影片生成、精準影片編輯和聲音生成版本。Meta指出,Movie Gen將成為Meta未來多項新服務的底層引擎,比如明年將用於IG,未來也會整合其他平臺產品。(詳全文)

3D 蘋果 Depth Pro
蘋果新模型1秒內將2D圖片轉為3D
蘋果日前展示最新視覺模型Depth Pro,能在不使用相機影像情況下,將2D圖片轉化成3D圖,在V100 GPU上0.3秒就完成。Depth Pro是一種零樣本單眼深度估計(Monocular depth estimation)的基礎模型,能在高解析度深度圖片中,加入細節銳利度,成為高品質3D圖像。
使用單眼深度估計技術的好處是,可應用於任何類型圖片,還能零樣本訓練出具可量測的深度,能準確重製物件形狀、場景布局。尤其,這種模型預測方法不需要感測器數據,即可準確預測,也能用任何單一圖片來合成想要的圖片。
在研究方法上,團隊使用2個視覺Transformer(ViT)模型,包括影像補片編碼器和一個影像編碼器,前者將圖片切成小補片,完成特徵提取、推論圖片像素的深度,後者以上下文訊息提升深度估計的準確性。在後處理階段,團隊以真實和合成資料集來提升量測準確性,以及物件邊界追蹤能力,再加上另一個影像編碼器模型提供的焦距估計,來優化3D圖片生成結果。最後,蘋果也發布Depth Pro模型程式碼和加權值。(詳全文)

Gemini Nano Android Google
輕量模型Gemini Nano開放測試
Google最近提供開發工具AI Edge SDK,Android開發者可用來試用Gemini Nano模型,打造各種場景的Android應用。進一步來說,Gemini Nano是Google Gemini系列模型之一,專門針對裝置端任務設計,模型可在裝置端完成所有運算,不需連接雲端伺服器。也就是說,敏感資料可留在裝置,且模型無需網路連線,也能提供完整功能。
Gemini Nano適用的場景有智慧回覆、文本改寫、校對或是文件摘要,開發者可透過AI Edge SDK整合,控制輸出隨機性、Top K和回應最大長度等推理參數,來滿足不同應用需求。目前,Google開放給開發者測試的是Gemini Nano 2模型,而且,Google也開發一套Android系統服務AICore,可讓開發者簡單在裝置端執行模型,不必自己發布執行環境、模型和其他元件。(詳全文)
Copilot Labs 微軟 瀏覽體驗
微軟發表新Copilot AI服務與功能
最近,微軟發表AI服務Copilot Labs,內含各種實驗性的新AI功能,首波新功能包括可理解使用者所查看網頁的Copilot Vision、能回答複雜問題的Think Deeper。其中,Copilot Vision是瀏覽器Edge的視覺AI助手,使用者允許,它就能與使用者正在閱讀的網頁互動,或是建議下一步,如摘錄、翻譯、尋找商品等。Think Deeper負責回答複雜問題,如使用者可詢問應該要搬到A城市還是B城市,或詢問哪款汽車最適合使用者的需求。
同時,微軟也推出能與使用者語音交流的Copilot Voice、可摘錄新聞或天氣消息的Copilot Daily,其中,Copilot Voice是一個AI語音助理,有4種不同聲音,可在所有支援Copilot的平臺上使用。但該功能目前僅支援英文,只在美國、加拿大、英國、澳洲及紐西蘭等市場推出。Copilot Daily則是Copilot Voice衍生服務之一,使用者可透過Copilot Voice聲音,來唸出新聞與天氣重點。Copilot Voice與Copilot Daily目前皆免費使用。此外,微軟還更新瀏覽體驗,使用者能直接在Microsoft Edge中的網址列,輸入@copilot來啟用Copilot,或輸入Bing generative search來體驗生成式搜尋。(詳全文)
PyTorch 運算效能 torchao
可大幅改進AI模型運算效能!PyTorch釋出torchao函式庫
PyTorch最近發布全新原生函式庫torchao,透過低精度資料型態、量化和稀疏性技術,減少模型的計算成本和記憶體使用量,讓模型執行更有效率。torchao提供一套容易上手的工具組,支援多種模型推論和訓練最佳化方法,可廣泛用於PyTorch模型,LLaMA 3和Diffusion模型的效能都顯著提升。
低精度資料型態是torchao加速的關鍵之一,該工具支援float8、int4等低精度資料型態,能有效減少計算成本和記憶體使用需求,像是在LLaMA 3 70B模型預訓練中,torchao提供了float8訓練流程,可將模型運算加速達1.5倍。在推論方面,torchao提供多種量化方式,包括權重量化和動態啟動量化。使用者可透過API自行選擇適合的量化策略,來達到最佳推論效能。稀疏性技術也是torchao提升模型效率的重要手段,有了稀疏性,torchao可最佳化模型參數計算,降低不必要的運算耗能。(詳全文)
多模態模型 NVLM Nvidia
Nvidia開源媲美GPT-4o的多模態模型NVLM 1.0
Nvidia在上個月發表多模態大型語言模型NVLM 1.0,號稱能與封閉的GPT-4o或開源的Llama 3-V 405B、InternVL 2等模型媲美,最近則開源NVLM 1.0模型權重,接下來還會提供基於Megatron-Core框架的程式碼。就NVLM 1.0模型設計來說,Nvidia先是比較解碼器架構模型,也採用交叉注意力機制模型,根據其優缺點提出一種全新架構,來提升訓練效率和多模態推論能力。
NVLM 1.0 72B在許多基準測試上雖然不是最突出,但在視覺語言及純文字任務上,都與Llama 3-V、GPT-4o、Claude 3.5 Sonnet和Gemini 1.5 Pro等模型相當,尤其在衡量光學字元辨識能力的OCRBench、自然圖像理解能力的VQAv2基準測試表現優異。NVLM 1.0 72B的指令遵循能力也不錯,且由於結合了OCR、推論、定位、常識、世界知識與程式碼撰寫等能力,綜合理解能力也更強大。(詳全文)

圖片來源/蘋果、Meta、Nvidia
AI近期新聞
1. OpenAI釋出更快的語音辨識模型Whisper large-v3-turbo
2. O1-engineer程式碼撰寫工具在GitHub上開源,以OpenAI API驅動
資料來源:iThome整理,2024年10月
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09

2026-02-10


2026-02-10

2026-02-10