
酷澎
靠ML/AI等大數據應用做到全韓國99%訂單於一天內送達的電商巨頭,如何將生成式AI融入開發與營運流程?近期,酷澎揭露了自家開發LLM與多模態LLM的方法與挑戰、如何將這些模型用來強化既有ML應用,以及投入新應用場景。
從傳統ML/AI到生成式AI
酷澎自稱無情的優化主義者(Ruthless Prioritization),數據人員遍布不同部門,使作業流程各個環節,都能利用數據分析技術來支持決策。在導入生成式AI之前,他們就已經應用AI/ML在搜尋、廣告、目錄整理與呈現、推薦、物流、定價、交通等領域。
其中,3種任務類別的ML模型占最大宗。首先是推薦系統模型,主要用於個人化和推薦介面,如電商、外送和娛樂應用程式中的首頁、搜尋和廣告。第二是內容理解模型,各產品團隊會透過產品目錄數據、用戶生成內容、用戶和商家數據等資料來源,讓模型理解產品、客戶和商家的特徵,並用於後續改善購物體驗。第三則是預測模型,也是酷澎打造超快速物流的關鍵推手。酷澎在韓國有超過100多座物流中心。預測建模在這些產品的定價、物流、配送方面扮演著關鍵角色。
甚至,為了管理大量ML專案,他們打造了一個ML平臺,來標準化開發與作業流程、促成管理CI/CD,並控管運算資源支出。一年內,這個平臺上執行了超過600個ML專案、10萬個工作流程。
LLM問世後,酷澎更開始用LLM及多模態LLM的文字及圖像理解能力,來強化既有AI/ML做法,上述類別的模型中。尤其,前兩類模型原就是利用超大量圖文資料進行推論,尤其適合用多模態LLM的圖文理解能力來增強。
酷澎3大常見LLM應用
酷澎內部常用的三大類LLM應用,包括了圖像與語言理解、大規模弱標籤生成,以及分類與屬性提取。
第一類圖像與語言理解。酷澎從實驗得知,利用多模態LLM同時根據圖像和文字數據,來生成嵌入向量,準確度高於單獨用用圖片向量或是單獨用文字向量的檢索。他們會將多模態向量,匯入其他下游ML模型,用於廣告資料檢索、相似性搜尋、商品推薦等場景。
另外,他們也會直接用LLM將韓文產品標題翻成中文、提升購物流中的圖像品質、摘要用戶評論,以及為產品和賣家生成關鍵詞。
第二類是大規模生成弱標註(Weak Labels)數據。準備ML模型訓練數據時,人工標註數據是成本高昂且困難的任務。尤其,酷澎同時需要英文、韓文和繁體中文語料,更凸顯了這個挑戰。
於是,他們用LLM,生成大量文本內容的標註。酷澎經實驗發現,這些標註用於弱監督式訓練時,效果可媲美人工標註資料。打造新領域ML模型時,缺乏過往高品質標註資料時,這種做法尤其有幫助。
第三大類則是分類與屬性提取。為產品分類和提取屬性時,酷澎舊有做法是為每個商品類別部署一個單獨的ML模型。這是因為,跨類別的分類模型,常常會對長尾商品產生準確度過低或雜訊過高的預測結果。隨著酷澎商品品項與類別增加,團隊也需要管理更多模型,造成了維運負擔。
相對於傳統ML模型,酷澎發現,LLM對產品標題、描述、評論、賣家信息等數據可以有更深入和準確的理解。他們不僅可以用單個LLM來支援分類系統,處理所有商品類別,甚至,還提升了不同分類的準確度。
酷澎LLM的開發周期與技術選擇
酷澎將LLM對齊任務目標的方法,依照難度與時間成本排序,分為情境內學習(ICL,In Context Learning)、檢索增強生成(RAG,Retrieval-augmented Generation)、監督式微調(SFT,Supervised Fine-tuning),以及持續預訓練(CPT,Continuous Pre-training)。其中,ICL和SFT是最常用的做法。
需要SFT或CPT時,酷澎LLM從測試到應用分為三階段。
第一階段是小規模測試,決定模型種類、模型參數規模、提示詞模板。準備數據時,酷澎利用Apache Zeppelin筆記本,來發派和管理Spark等大數據處理工具。測試模型及提示詞模板作業,在GPU容器中的Jupyter筆記本進行。
第二階段是實際訓練,進行微調或預訓練,並評估模型成效。酷澎最常使用DeepSpeed Zero作為訓練框架,看重此框架快速完成訓練設定的能力及對Hugging Face上大多數熱門模型的支援度。
模型訓練環境,酷澎選擇Kubernetes分散式Training operator上的平行模型訓練功能,PyTorchJob,並使用Polyaxon來管理更細緻的ML訓練生命周期。酷澎的LLM訓練周期,與既有ML訓練周期的步驟相同。
第三階段則是投入應用,常見做法包括蒸餾與嵌入。前者是從訓練好的LLM蒸餾出較小模型,用於即時推論。後者則是利用LLM生成嵌入向量,應用於其他ML模型中。
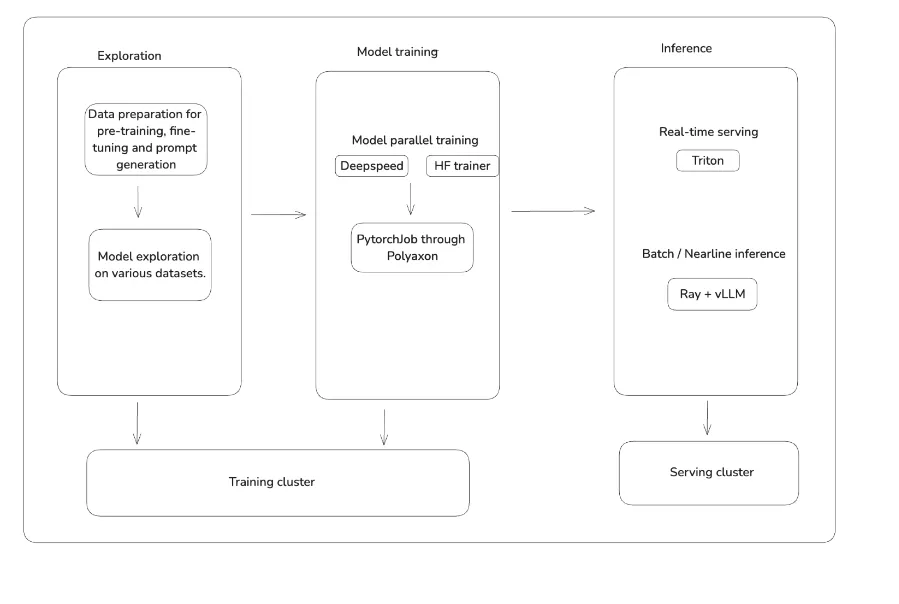
他們使用OpenAI推出來用GPU開發開發機器學習演算法的程式語言Triton,來從LLM提取出推論內容,用於蒸餾或嵌入。要打造同時利用CPU和GPU處理的推論管道(Inference Pipeline)時,使用Ray和vLLM。
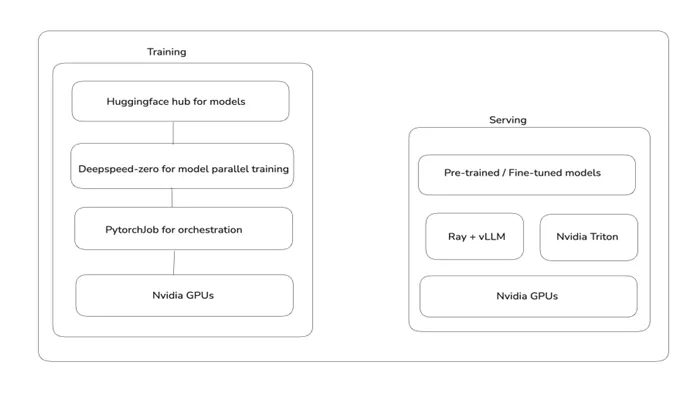
酷澎主要選用中文、韓文及日文語言表現比較強的開源模型,包括Qwen、Llama 3、Orion、Polyglot、Orion、T5、BERT等,並根據不同應用場景,選擇不同參數規模版本。翻譯、標註生成、RAG用途的模型,選擇100億個參數以上版本;實體抽取(Entity extraction)及關鍵字生成,使用10億到100億個參數版本;生成嵌入向量等用途,則使用10億以下版本。
如何因應硬體限制的挑戰
導入生成式AI前,酷澎ML訓練架構沒有支援分散式訓練,且部署架構完全使用CPU。這使他們大規模導入生成式AI後時,需要大量增添供應短缺且要價昂貴的GPU資源。
為了控管GPU支出及確保可用性,酷澎模型構建團隊會定期進行基準測試,以評估不同GPU應用於不同模型的訓練和推論時,各自的價格與性能比例。這樣一來,就能更準確根據作業所需算力規模,來分配硬體資源。尤其,測試和應用參數規模較小的時LLM時,能放心使用性能較低的設備。
訓練模型時,他們也採取跨區及混合雲模式來調度硬體資源。這包括使用亞太及美國區域的雲端GPU資源,以及地端A100/H100資源。不過,隨之而來的挑戰是確保基礎架構(存儲與網路)和開發者體驗的一致性,目前他們仍未完全解決。
酷澎也持續嘗試新技術,來提升生成式AI工程效率,並降低硬體需求。例如,他們嘗試用vLLM推論框架,將許多推論作業的吞吐量提升了接近20倍。他們也嘗試將模型參數卸載到CPU的技術,成功搭配低RAM數的GPU來微調LLM,有效紓緩高端GPU需求。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-10

2026-02-09


2026-02-10

2026-02-13