Snowflake宣布開源一系列基於SwiftKV技術強化的Llama 3.1模型,這項創新技術能大幅縮短大型語言模型的推論時間,最高可達50%。SwiftKV不僅突破了傳統的鍵值(Key-Value,KV)快取壓縮技術,更針對模型推論階段的計算瓶頸進行全面改進。通過結合模型重組與知識保存自我蒸餾的方法,SwiftKV有效提升吞吐量、降低延遲與運算成本,為企業部署大型語言模型應用提供更高效且經濟的解決方案。
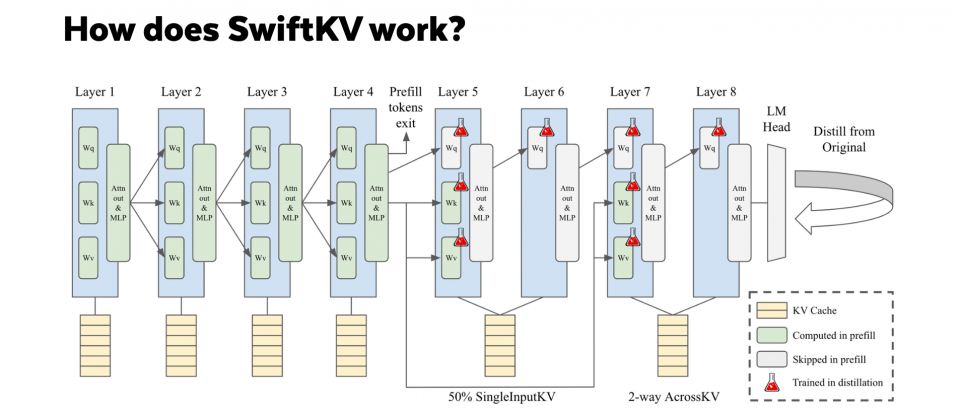
SwiftKV的重點在於改進輸入提示的處理過程,研究人員提到,這是企業大型語言模型應用中計算資源消耗的主要來源。在大型語言模型推論過程中,模型會生成大量用於注意力計算的KV快取,這些快取包含關鍵資訊(Key)和相關資料(Value),幫助模型在輸入與輸出之間建立關聯。Snowflake的研究顯示,多數企業工作負載的輸入提示長度約為輸出生成內容的10倍,而現有的KV快取壓縮方法無法有效解決這部分的計算需求。
為此,SwiftKV引入了SingleInputKV技術,利用模型層輸出的相對穩定性,允許部分Transformer層跳過計算,直接生成後續所需的KV快取。這一技術不僅大幅降低計算量,還保持了模型的整體準確性,經測試平均僅損失約1%的準確性。
實驗結果顯示,SwiftKV在Llama 3.1 80億參數和700億參數模型上表現出色。對於高負載批次處理使用案例,SwiftKV可將總吞吐量提升至基準模型的2倍,而在即時互動使用案例中,則顯著降低了首字元生成延遲(TTFT)與後續生成時間(TPOT)。這種效能提升對需要處理大量長輸入的應用場景,如程式碼完成、文本摘要和檢索增強生成等應用特別適合。
此次開源還包含SwiftKV的推論模型檢查點與知識蒸餾工作管線。Snowflake表示,未來將繼續改進相關工具,進一步降低大型語言模型的運算成本與資源需求。對於企業來說,SwiftKV可在不犧牲效能的前提下,大幅提升生成式人工智慧應用的經濟效益。
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
2026-02-09
")
")
2026-02-09

2026-02-09