")
美國華盛頓及史丹佛大學研究團隊發表<s1: Simple test-time scaling>研究,以僅1,000個問題資料集訓練出s1-32B模型,並在數學測驗AIME24及MATH等標竿測試成果超越o1-preview。(圖片來源/arXiv:2501.19393)
美國華盛頓大學及史丹佛大學研究團隊本周公布最新研發成果,以極低成本使用新開發方法,可以小樣本資料集訓練出推論效能超過o1-preview的AI模型。
成員來自華盛頓大學及史丹佛大學的研究團隊發表論文,他們以僅1,000個問題資料集訓練出s1-32B模型,並在數學測驗AIME24及MATH等標竿測試成果超越o1-preview。
目前業界大型語言模型主要是以大規模運算訓練提升模型能力,OpenAI o1模型已開始使用這種新興方法。但上述研究團隊探索以最簡單方法進行測試時擴展(test-time scaling)建模,且實現強大的推理能力。研究人員嘗試小樣本訓練;他們集結1,000道問題,以及從Gemini Thinking Experimental生成的答案及推理過程組成s1K資料集。在環境上,團隊在16顆H100 GPU平臺上執行Qwen2.5-32B-Instruct進行監督式微調。
研究人員告知Techcrunch,他們僅花了20美元租用設備進行此次開發。
在測試期間他們使用了名為「Budget Forcing」的方法控制推論時間。最後,研究人員將訓練出的s1-32B與市面主要非開放及開放模型進行標竿測試比較。在MATH及AIME24中,s1-32B超越o1-preview,而在擴展後,還可進一步提升AIME24測試成果由50%提升為57%。
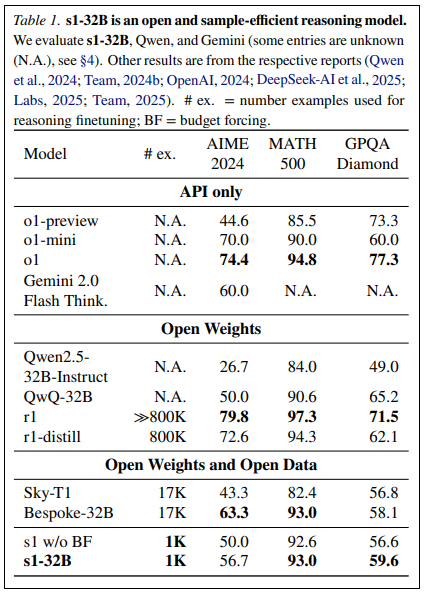
研究團隊也比較了s1-32B和DeepSeek r1和o1,測試結果並不如後二者。但研究團隊解釋,這是因為DeepSeek r1和o1都使用了大量數據進行強化學習,而s1-32B則僅使用1,000個精選資料進行微調,因此仍是最具樣本效率的模型。
本模型已開源於GitHub上。
大學研究人員不斷在以更低成本訓練高效能AI模型。今年初柏克萊大學研究團隊也用了約450美元來訓練效能近似o1-preview的模型。
熱門新聞

2026-02-09

2026-02-10

2026-02-06

2026-02-09

2026-02-10

2026-02-10

2026-02-09
