
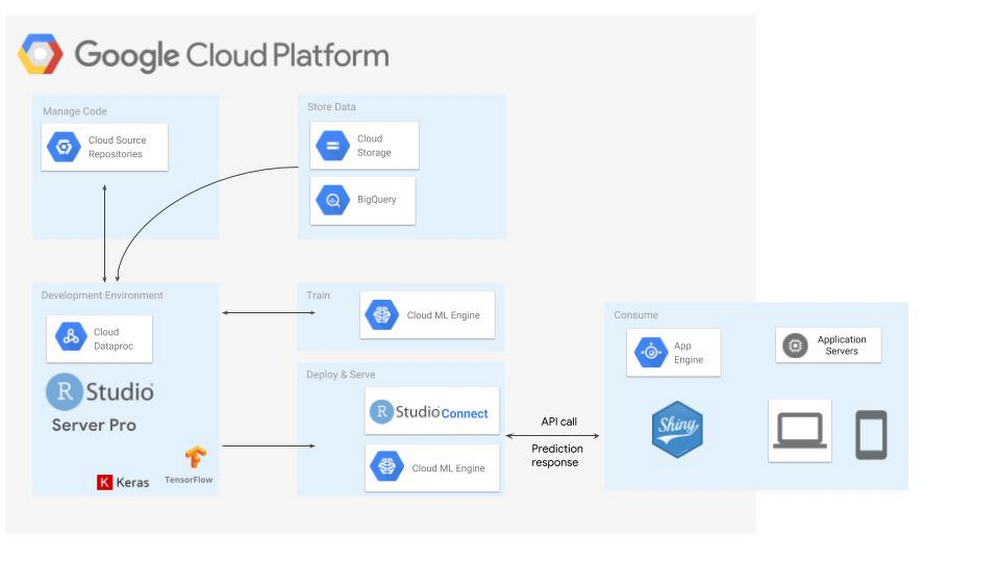
GCP宣布在其Cloud Dataproc服務上釋出SparkR作業的測試版,供資料科學家在需要擴展分析規模的時候,利用託管的運算資源。使用者可以選擇使用雲端伺服器版的RStudio,以獲取備份與高效能執行的優點。
R語言通常用建構資料分析工具和統計應用程式,而SparkR是一個輕量級的前端套件,供開發者在Apache Spark上開發R語言應用,而這整合讓R開發人員可以,使用類似dplyr的資料操作語法,操作儲存在雲端各種大小的資料集。SparkR還支援使用MLlib進行分散式機器學習,使用者可以用來處理大型雲端儲存資料及或是運算密集的工作。
而Cloud Dataproc是GCP的完全託管雲服務,使用者能以簡單且高效能的方式執行Apache Spark和Apache Hadoop叢集。 Cloud Dataproc工作API可以輕鬆的將SparkR工作分派到叢集中,無需開放防火牆才能利用網頁IDE或是SSH存取主結點,而且藉由工作API,可以自動重複在資料集上進行R統計。在GCP上使用R可以避免因為基礎設施所帶來分析上的限制,使用者可以自由建構大型模型,以分析過去需要高效能計算基礎架構才能運算的資料集。
雖然SparkR工作API提供簡單的方式,執行SparkR程式碼並自動運行任務,但大多數R開發人員仍習慣使用RStudio進行探索性分析,而GCP上的R也提供開發人員熟悉的RStudio介面。而提供介面的RStudio伺服器可以在Cloud Dataproc主節點、Google Compute Engine虛擬機器,甚至是在GCP之外運行都可以。
開發者可以選擇在GCP上創建RStudio伺服器,並在不需要的時候關閉,開發者還可以選擇RStudio的商業發行版RStudio Pro。Google表示,雖然從桌面連接到雲端是一種使用RStudio的方法,但大多數R開發人員仍喜歡使用雲端伺服器版的RStudio,從任何工作地點獲取桌面設定,在個人電腦之外備份工作,並將RStudio設置在與資料來源相同的網路中,利用Google的高效能網路可以大幅提高R應用的效能。
在Cloud Dataproc上執行RStudio的另一個優點,是開發者可以利用Cloud Dataproc自動擴展功能(Autoscaling),在開發SparkR邏輯時可以使用最小叢集規模,一旦工作需要大規模處理時,開發者不需要修改伺服器,只要將SparkR工作提交給RStudio,Dataproc叢集便會根據設定的區間,自動擴展以滿足工作需要。
GCP上的運算引擎能良好的擴展R的統計功能,透過BigQuery套件包,開發者能查詢BigQuery表格並檢索相關專案的元資料、資料集、表格和工作。在Cloud Dataproc上執行SparkR套件時,可以使用R來分析和建構儲存在雲端中的資料。
一旦探索完畢,準備進入建模階段,開發者可以使用TensorFlow、Keras和Spark MLlib函式庫,TensorFlow存在R介面能夠利用進階Keras和Estimator API,而需要更多控制時,開發者也能擁有完全存取核心TensorFlow API的權限。Dataproc上的SparkR工作允許開發者大規模訓練和評分Spark MLlib模型。另外,想要大規模訓練和託管TensorFlow和Keras模型時,也可以使用R介面存取雲端機器學習引擎,直接讓GCP代為管理資源。
熱門新聞

2026-02-11

2026-02-09

2026-02-10
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-06

2026-02-10

2026-02-10

2026-02-10