
Google釋出了自家機器學習加速器TPU的新消息,新一代TPU v4的效能將是前一代TPU v3的2倍以上,同時Google也發表了在機器學習的最新進展,於MLPerf基準測試6個模型打破了目前的訓練速度紀錄,在DLRM模型訓練上,速度甚至是之前紀錄維持者的2.8倍。
Google表示,他們打造了目前世界最快的機器學習訓練超級電腦,使用專為人工智慧設計的張量處理單元(TPU),在6項MLPerf基準測試中,與其他非Google最快的紀錄相比,Google刷新了效能紀錄。
這6個模型分別是用於排名與推薦的DLRM模型;常用於自然語言處理的Transformer;還有Google搜尋所使用的BERT模型;廣泛用於圖像分類的ResNet-50模型;可在行動裝置上執行的輕量級物體偵測模型SSD;以及圖像分割模型Mask R-CNN。
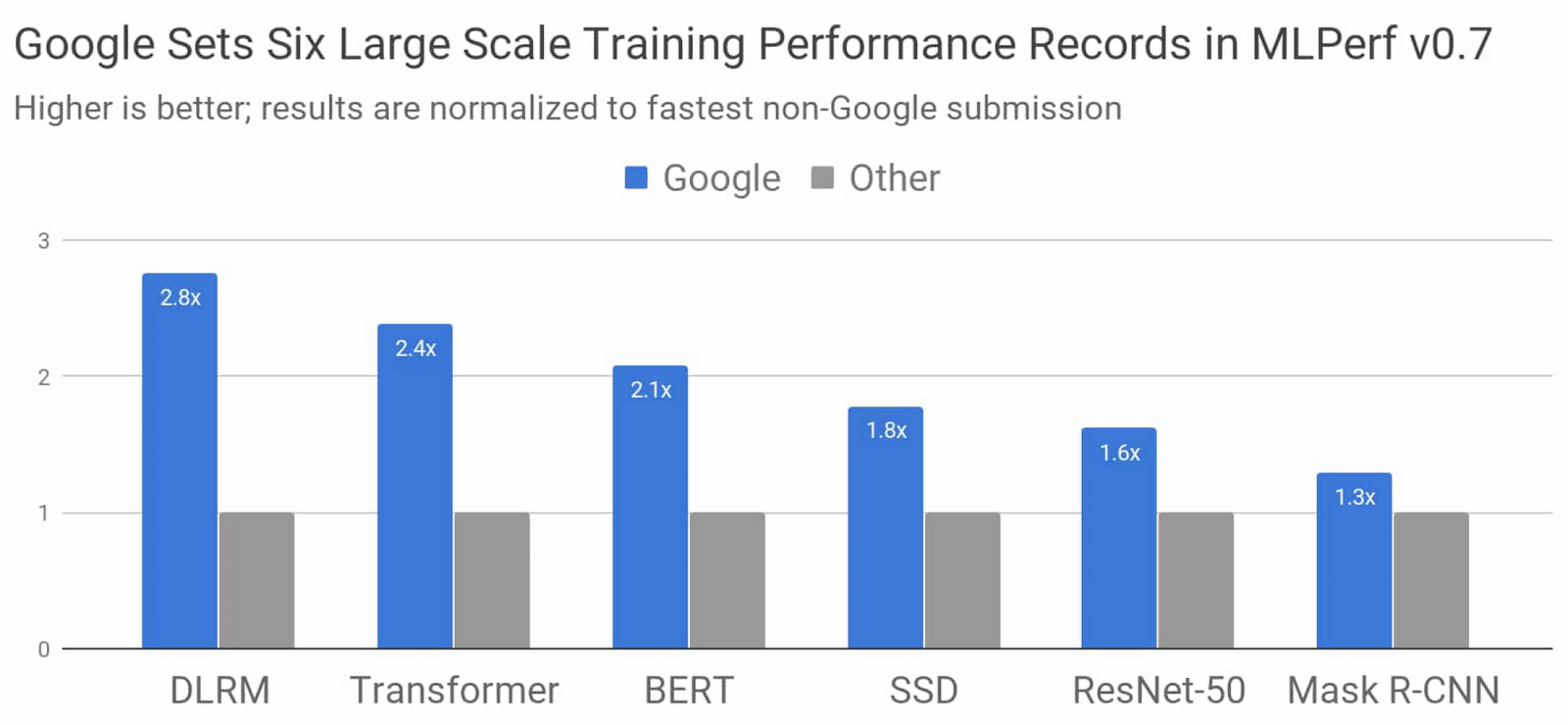
這次Google所使用的超級電腦,規格是Cloud TPU v3 Pod的4倍,具有4,096個TPU v3晶片,與搭載數百顆CPU的主機,這些運算資源以超高速大規模的專用網路相連,最高可以輸出430 PFLOPs高峰效能。
Google使用TensorFlow、JAX和Lingvo中的機器學習模型實作,從零開始訓練Transformer、SSD、BERT以及ResNet-50模型,訓練時間皆在30秒之內,之所以這件事值得一提,Google表示,在2015年時,即便用最快的硬體加速器,訓練其中一種模型,都需要花費3個多星期,而Google所使用的超級電腦,相當於把相同模型的訓練速度提升5個數量級。
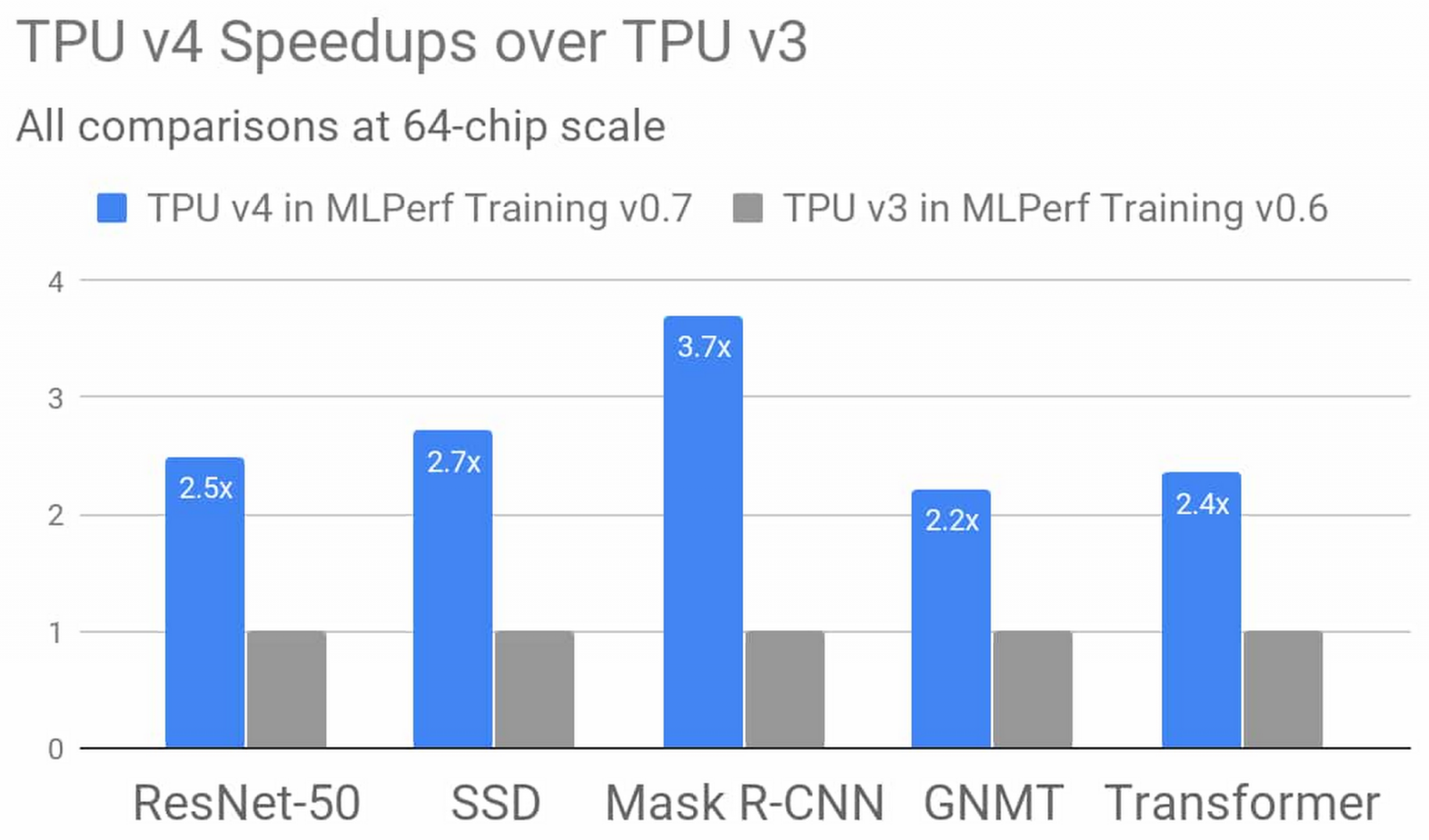
而Google最新的第4代TPU,較前一代TPU v3,擁有兩倍的矩陣乘法效能,而且記憶體頻寬大幅增加,內部相連技術也獲得改善,利用MLPerf基準測試比較TPU v4和TPU v3,TPU v4平均效能提升2.7倍,最大的效能差異是用於訓練Mask R-CNN,TPU v4的效能是TPU v3的3.7倍。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-09

2026-02-06

2026-02-09