臉書
臉書昨(19)日宣布將首個不需透過英語、可直接翻譯兩種語言的AI模型M2M-100開源出來。
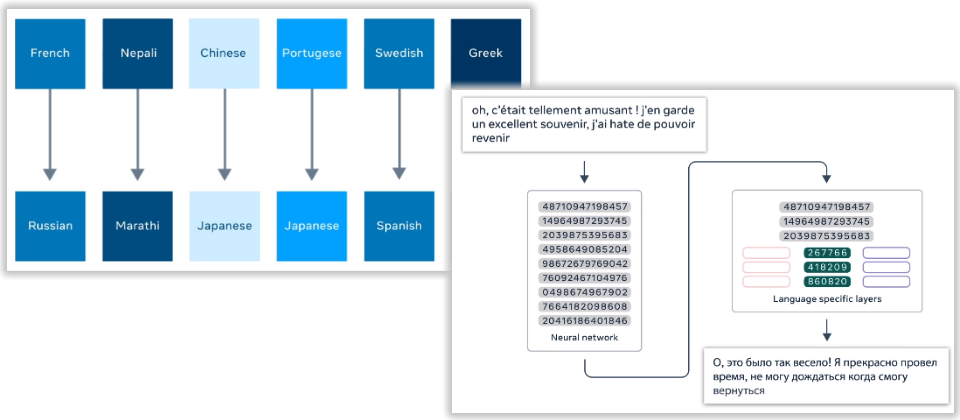
臉書指出,一般機器翻譯需要為每種語言及每種任務建立一種AI模型,由於英語訓練資料較充裕,因此形成以英語為中心的翻譯模式;碰上要翻譯非英語的兩種語言,例如中文和法文時,大部份機器翻譯採取法文翻成英文,再由英文翻成中文。臉書指出,這種需要以英文為中介的翻譯會導致原意流失或翻譯錯誤,並不適合臉書平臺上160多種語言貼文翻譯的需求。
今天於GitHub釋出的M2M-100是臉書AI多年機器翻譯研究的成果。它是第一個不需仰賴英語直接為100種語言中的2種進行翻譯的單一多語言機器翻譯(multilingual machine translation,MMT)。臉書解釋,該公司利用新的探勘技術取得翻譯資料,並以找來的1000億句子為基礎建立「多對多」的資料集,這個多對多系統也是第一個使用臉書最新PyTorch library Fairscale的系統,形成的資料集包含100種語言、2,200 種翻譯方向(如中文到法語算一種)的75億句子。最後他們使用多種技術來訓練這個具備150億個參數的單一模型。
臉書指出,名為M2M-100的模型可蒐集相關語言資訊,反映更多元化語言及構詞學的面向。臉書聲稱,根據一次BLEU(bilingual evaluation understudy,比較機器翻譯和1個以上人工參考翻譯的品質量測)測試下,該模型和傳統雙語翻譯效果一樣好,並比臉書現在以英文為中心的多語言翻譯模型還高出10分。
臉書表示未來計畫以M2M-100來取代現行使用的機器翻譯模型,來提升平臺上的語言翻譯品質,特別是數百萬人使用的弱勢語言。
熱門新聞

2026-02-13

2026-02-13

2026-02-13

2026-02-13

2026-02-13


2026-02-13
