
KPMG報告截圖
重點新聞(0507~0514)
KPMG 企業AI大調查 底層架構
KPMG全美950家企業AI大調查:培養人才仍是挑戰、多數還沒建好底層基礎架構
KPMG最近公布今年份的企業AI大調查結果,發現企業擁抱AI時仍有AI人才不足、工具選擇和基礎架構不足的挑戰。這份調查於今年1月展開,針對全美950家來自製造、科技、金融、醫療、生命科學、零售和政府等領域的企業來詢問,這些企業年收必須超過10億美元,但醫療和生命科學除外,門檻為1億美元。
調查發現,高達9成受訪企業下功夫讓員工跟上AI趨勢、努力讓員工學習新AI技能,但對醫療和政府單位來說,分別只有8成和約7成的執行長做到這2點。不過,在這9成中,高達97%的製造業執行長稱自家員工大致具備AI所需的技能;調查也發現,比起經理等級的主管,上層CXO對自家人才的AI技能反而更樂觀。不過,KPMG指出,調查中仍有許多企業難以招募所需人才,來發展企業AI策略並實踐。
另一方面,調查也發現,企業還有2個技術挑戰,也就是找到合適的AI工具和平臺,以及建立發展AI所需的底層架構。針對第一點,KPMG解釋,這是因為市場變化快速,大部分企業擔心今天購買採用的工具,到明天又有更好更快的工具、平臺或API出現,這就造成投資錯誤,就連推動AI發展的科技業,也有6成執行長同意。
再來,許多企業尚未投資時間和金錢,來打造底層資料處理架構,甚至還有滿多企業未將IT系統上雲(比起老舊運算環境,雲更容易擴展AI、進入生產)。KPMG指出,這些企業不情願上雲的主因是,建立模型治理制度來保護資料太繁瑣,而且,整理這些資料來訓練模型、維護模型,也太耗費心力。 (詳全文)
Google Transformer MUM
屢屢突破NLP天花板,Google發表比BERT強1,000倍的Transformer模型
Google在年度開發者大會上發表基於Transformer架構的NLP模型MUM,號稱比NLP里程碑模型BERT還要強上1,000倍,不只能理解語言,還能生成各種回答,更可一次讀懂文字和圖像。
Google近年屢屢突破NLP天花板,從2013年發表Word2vec演算法、靠著將文字轉換為向量提高精準度,再到2017年提出Transformer架構、發表NLP大型訓練模型BERT,一舉拿下各種測試的SOTA後,最近又一口氣發表可理解、可生成的模型MUM,以及可順暢進行開放式對話的LaMDA。
以MUM來說,Google一次用75種語言和多種任務來訓練MUM,來讓模型發展完整的理解力和世界知識,這是前幾代模型做不到的。再來,MUM是多模態模型,也就是說,它可一次理解語言和影像這2種型態的資料,而且,「未來還能理解音訊和影片,」Google強調。
但Google會怎麼運用MUM呢?Google解釋,由於MUM可理解文字和圖片,因此可同時分析網頁和圖片資訊,改善搜尋體驗。比如,使用者可拍一張登山靴照片,然後問Google:「我可以穿這雙靴子登富士山嗎?」這時,MUM會分析照片和問題、給出回答,甚至帶使用者到專門介紹登山裝備的部落格。 (詳全文)
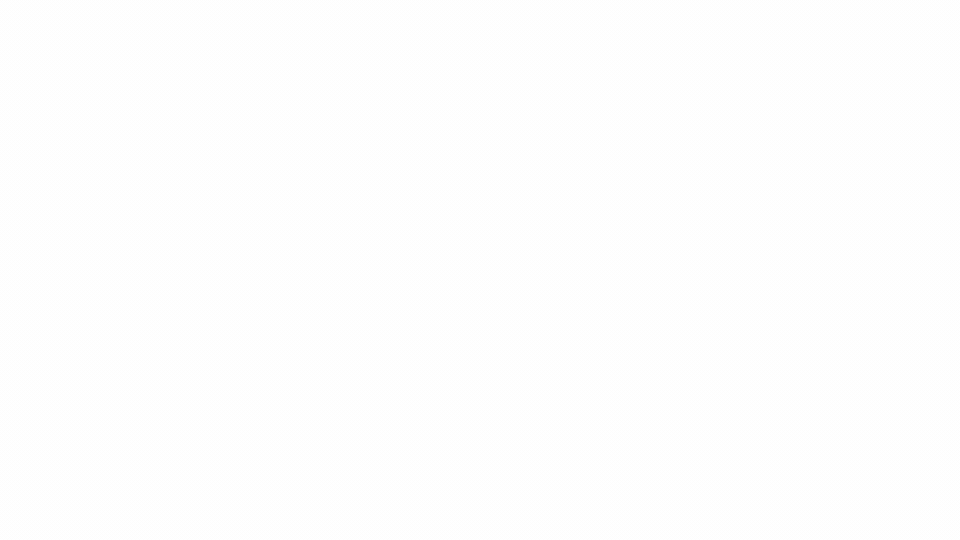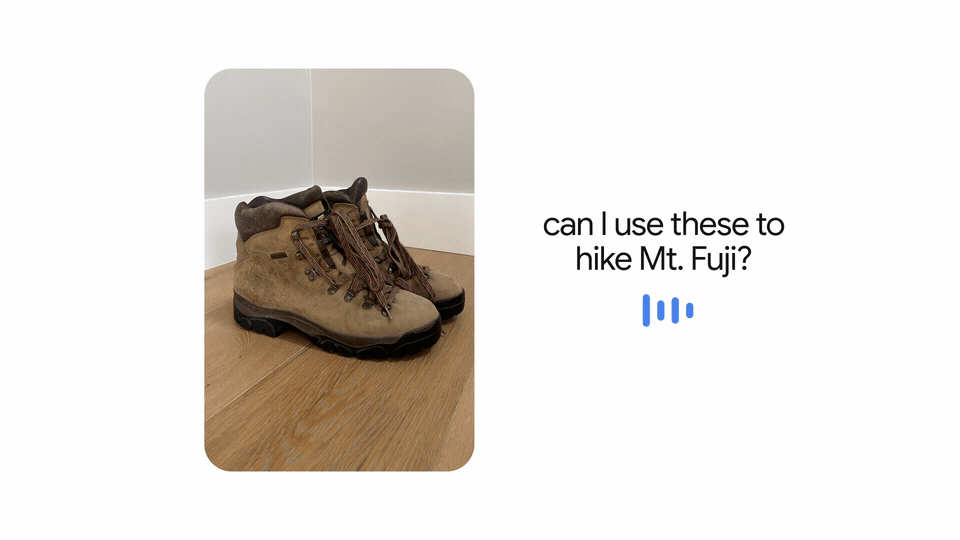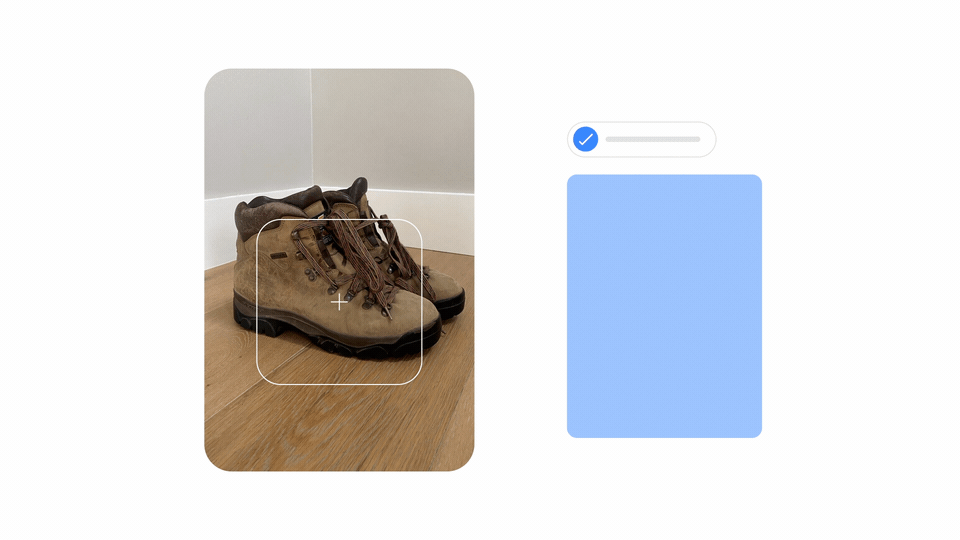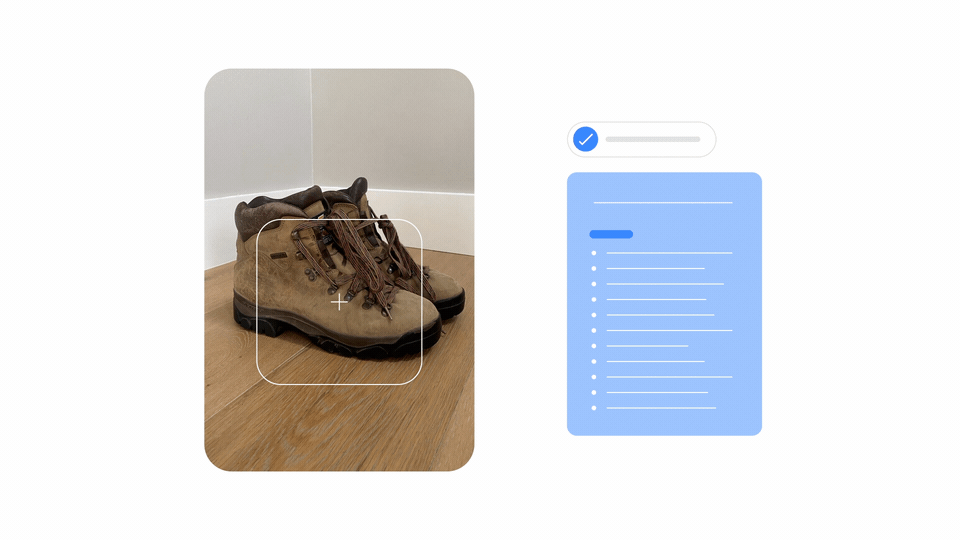
對話模型 LaMDA Transformer
Google再推可聊各種話題的開放式對話模型LaMDA
Google在自家開發者大會I/O上,揭露一款基於Transformer架構的自然語言預訓練模型LaMDA,可順暢進行各種議題的開放式對話,打破傳統Chatbot的限制。
Google表示,有別於其他Transformer模型(如BERT、GPT-3),LaMDA用對話資料訓練而成,並用幾個特徵來確認輸入值是不是開放式對話,其一就是「有沒有道理」。在I/O上,Google就用LaMDA來模擬冥王星與紙飛機的對話,比如能回答「我知道你很好奇,儘管問吧」、「(你來冥王星的話)你會看到一個大峽谷和一些冰山」,比現有Chatbot表現要好。目前LaMDA仍處於研究階段,未來Google將用來改善搜尋服務和語音助理,就像用BERT來改善Google搜尋的內容品質那樣。(詳全文)

OpenAI 新創基金 Azure
1億美金支援還有專屬系統、Azure點數可以用!OpenAI推出AI新創基金專案
OpenAI近日啟動OpenAI新創基金專案,投資1億美元來扶植幾家「對世界有深遠、正面影響的AI新創」,特別是醫療、氣候變遷、教育和個人服務等能帶來變革的領域。
這些基金由微軟等OpenAI的合作夥伴提供,並由OpenAI管理。獲選的新創不只能得到OpenAI團隊支援,還可使用OpenAI新系統,並獲得微軟Azure服務點數。OpenAI還有2個招募準則,一是歡迎採用他們API的新創,二是歡迎來自少數群體的創辦人。(詳全文)
非監督式學習 語音辨識 轉錄資料
不用轉錄資料就能自己學習、效能媲美監督式模型!臉書發表非監督式語音辨識模型
臉書發表一套非監督式語音辨識技術Wav2vec-U,不需把語音轉錄成文字資料,就能訓練模型。而且Wav2vec-U的效能,比幾年前用1,000小時轉錄語音資料訓練的監督式模型還要好。
臉書指出,目前語音辨識系統只對少數主流語言友善,這是因為,這些主流語言有大量的轉錄音訊資料,可用來訓練高品質的模型。但對其他語言、方言來說,就難以取得足夠資料。
因此臉書開發Wav2vec-U,結合k-平均演算法,能從未標記的音訊中學習語音結構,將語音分割出各對應的語音單元,因此不需要轉錄音訊資料。為學習辨識語音中的單詞,團隊利用GAN中的生成器產生音位序列,再透過鑑別器來判別相似度,直到生成器成功騙過鑑別器。後來,臉書也在Swahili和Tatar等小眾語言測試模型,並與其他模型比較。在TIMIT基準測試中,與最佳的非監督式方法相比,Wav2vec-U錯誤率降低57%。(詳全文)

ML生命週期 ML平臺 MLOps
如何有效管理ML生命周期?Google推出一站式ML平臺
Google在開發者大會I/O上,正式推出全託管機器學習平臺Vertex AI,由一系列Google內部所使用的機器學習工具組成,提供統一的UI和API來操作Google雲端服務,加速企業AI模型訓練、部署和維護。
Google指出,不少資料科學家採用拼接的ML解決方案和不順暢的開發流程,導致模型開發和實驗受阻,而Vertex AI可解決這個問題。Vertex AI包括原用於Google內部的AI工具,如電腦視覺、語言處理、對話和結構化資料等。
該平臺也提供一系列MLOps工具,強調不具專業ML經驗也可使用,像是可提高實驗速度的Vertex Vizie,和用來共享、重用ML功能的Vertex Feature Store,以及可加速生產環境模型部署的Vertex Experiments。Vertex AI也支援邊緣AI應用,Vertex ML Edge Manager讓用戶可使用自動化流程和API,在邊緣部署和監控模型。Vertex Model Monitoring、ML Metadata與Pipelines等,主打自助模型維護和可重複功能來簡化端到端ML工作流程。(詳全文)
Google Health AI工具 網頁版
皮膚有問題怎麼辦?Google今年要發表網頁版的皮膚病AI工具
Google Health開發一套可幫忙診斷皮膚病的AI,使用者只要用手機拍下患部,再回答相關資訊,這個AI工具就能分析可能的疾病。目前,這套AI已取得歐盟一級醫療裝置的CE認證,Google也準備在今年發表網頁版應用。
Google Health說明,每年Google搜尋數據中有10億次是關於皮膚、指甲和頭髮的問題,而且全球有20億民眾深受皮膚病之苦,卻沒有足夠的皮膚病專家。為緩解問題,Google開發這套模型,使用者只要拍攝和上傳有狀況的皮膚、頭髮或指甲等3個不同角度的照片,再回答如年紀、性別、種族、皮膚類型、狀況維持多久等問題,或提供其它症狀等資訊來縮小範圍,AI工具就會分析,從288種皮膚疾病中找出適合的幾種狀況供參考,並提供這些疾病的醫生見解、常見問題,以及網路上的相關照片。 (詳全文)
圖片來源/KPMG、Google、臉書
AI趨勢近期新聞
1.微軟Power Apps嵌入GPT-3,把自然語言變成程式碼來開發應用
2. AWS ECS Anywhere正式GA!
資料來源:iThome整理,2021年5月
熱門新聞

2026-02-09

2026-02-10

2026-02-06

2026-02-09

2026-02-10

2026-02-10

2026-02-10

2026-02-09