
生成式AI新創MosaicML最近開源70億參數語言模型MPT-7B-8K,可處理的文長達8k Token。
MosaicML
重點新聞(0714~0720)
MosaicLM 文長 MPT-7B-8k
一次可處理8千個Token,MosaicML開源新語言模型還可商用
生成式AI新創公司MosaicML最近開源一款70億參數的語言模型MPT-7B-8K,且一次可消化的文長達到8千個Token,擅長處理長文重點摘要和問答,還能在MosaicML平臺上根據特定任務,進一步微調。
進一步來說,該模型用1.5兆個Token(通常指單字或單位更小的詞根、詞綴)訓練而成,並以256個H100 GPU花3天完成模型訓練。這次釋出的模型有3個版本,包括MPT-7B-8k、MPT-7B-8k-Instruct和MPT-7B-8k-Chat,其中,第一個版本是以Transformer解碼器為基礎,並以FlashAttention和FasterTransformer機制來加速訓練與推論,能處理上下文長8千個Token的輸入,目前開源、允許商用。第2個版本是以第1個微調而成,可處理長篇指令,特別是摘要和問答,一樣開源且可商用。第3個版本則是Chatbot類的生成式模型,是額外用15億個聊天數據Token微調第1版模型而成,開源但不允許商用。(詳全文)
.png)

Llama 2 微軟 Meta
Meta和微軟聯手發表可免費商用的大型語言模型Llama 2
最近,Meta開源可免費商用大型語言模型Llama 2,並找來微軟當作首批發表合作夥伴。用戶現能在Azure和Windows上部署Llama 2模型,可降低企業開發AI應用的成本和障礙。
今年2月,Meta發表第一代LLaMA,僅開放AI研究社群申請使用。LLaMA以大量未標註的資料訓練而成,有70億、130億、330億及650億個參數等版本,用戶可針對各種任務進行微調。現在,Meta開源Llama 2不限研究用途,免費提供商用,但若用戶開發的應用程式月活躍使用者超過7億人,就得另外取得Meta的模型使用同意授權。Llama 2的訓練資料量比第一代多出40%,共使用2兆Token,且其文章上下文長度(即模型生成文本時參考的文章長度)是第一代的2倍,可生成更長的回覆。此外,Llama 2經調校的版本,使用了超過100萬個人類標註的資料訓練。Llama 2開源內容包括預訓練模型、經調校模型的權重和起始訓練程式碼,並有70億、130億和700億參數等版本。(詳全文)
電腦視覺 CM3Leon 生成式AI
Meta發表通用生成模型,文生圖、圖生文都可以
Meta日前發表可同時支援文字和圖像生成的通用模型CM3Leon,是一款由純文字語言模型配方所訓練的多模態模型,號稱圖像生成所使用的訓練運算資源是其它方法的1/5,就能達到進階表現,但Meta並未開源該模型。
CM3Leon是個基於Token、檢索增強和解碼器的模型,它採用因果隱蔽混合模態(CM3)架構,也就是模型可以只關注之前的元素,來生成輸出序列,確保生成內容的連貫性,還能在訓練過程中忽視或隱蔽某些元件,來產出更好的結果,還能同時處理文字和圖像的輸入。該模型只用了30億個Token文字資料訓練而成,比現有同類模型OpenFlamingo的400億個Token與Flamingo的1,000億個Token要少,還能執行更多任務。
Meta強調CM3Leon是個通用模型,單一模型就能處理多種任務,如以文字描述來生成圖像、以文字描述來編輯圖像,或是要求該模型替圖像生成圖說等,比如替《戴珍珠耳環的少女》戴上墨鏡,或輸入文字調整圖片天空的顏色。(詳全文)

SIGIR 生成式AI 資訊檢索
AI頂級會議SIGIR在臺舉辦,Google、微軟兩大巨頭分享生成式IR新進展
國際頂級AI學術會議又來臺舉辦,資訊檢索領域(IR)的AI頂級會議ACM SIGIR自7月23日起在臺北展開,由Google DeepMind 、微軟研究院的重量級科學家開場,分享生成式檢索、Copilot搜尋等AI新典範浪潮下的研究進展,多家跨國企業像摩根大通集團都派出研發副總來臺分享業界第一手研究。
ACM SIGIR是全球13個頂級AI會議之一,是資訊檢索領域公認最重要的學術會議,今年有將近500篇論文,論文接受率平均只有20%,議題涵蓋各種資訊檢索技術和議題,例如搜尋、排序、評估、NLP、推薦系統、內容分析、FATE(公平透明倫理、可解釋性)等。而傳統的IR技術,正是電商、企業常用推薦技術背後的基礎,此外也有業界研發成果專場,不只學術界重視,連科技巨頭、跨國企業,如摩根大通集團都有數篇論文發表,派出研發副總親自登臺。2019年7月臺大人工智慧研究中心陳信希主任在向SIGIR組織提出申請,與三國競爭後勝出。這是46年來首次來臺舉辦,也是2019年電腦視覺頂級會議ICIP登臺,帶來卷積神經網路之父Yann LeCun訪臺後的另一場AI頂級會議。(詳全文)
GitHub Copilot Chat 寫程式
GitHub Copilot Chat開放企業測試
GitHub在20日宣布,以GPT-4為基礎的程式開發助理Copilot Chat,正式開放給GitHub Copilot for Business的企業用戶測試。今年3月,GitHub發表Copilot X開發輔助工具,Copilot Chat就是其中一項。GitHub Copilot X是GitHub Copilot的升級版,整合了最新大型語言模型GPT-4,最大特色是加入Copilot Chat聊天介面和語音寫程式能力,以及更強的程式開發輔助。
這次宣布則是將Copilot X推向企業,提供GitHub Copilot for Business用戶測試,可在開發環境Visual Studio和VS Code中,用Copilot Chat輔助撰寫程式。GitHub表示這讓Copilot IDE具備情境感知能力的對話助理,開發人員以自然語言輸入提示,即可執行困難的開發或除錯工作。(詳全文)
Teams 摘要 Copilot
可自動摘要會議內容!微軟Teams加入Copliot
微軟在Teams通話和聊天功能整合AI助理Copilot,使用者能從任何裝置上的Teams app撥打和接聽電話,還能以自然語言下指令,讓Copilot即時整理重點,如姓名、日期、電話號碼或工作等。
這個功能在客服上十分有用,像是能抓住客戶的產品功能、效能和價格等問題,還能紀錄客戶的回饋,並建議接下來的步驟。而Teams chat加入Copilot後,用戶可指示AI聊天機器人整理出對話串重點,幫助管理不同對話、提高工作效率。Copilot提供過去1天、7天或30天的提示選項,讓用戶不需再拉回前面讀取落落長的對話。(詳全文)
Hugging Face AI WebTV 生成式AI
Hugging Face推出AI WebTV平臺,幫你測試影片、音樂生成AI的表現
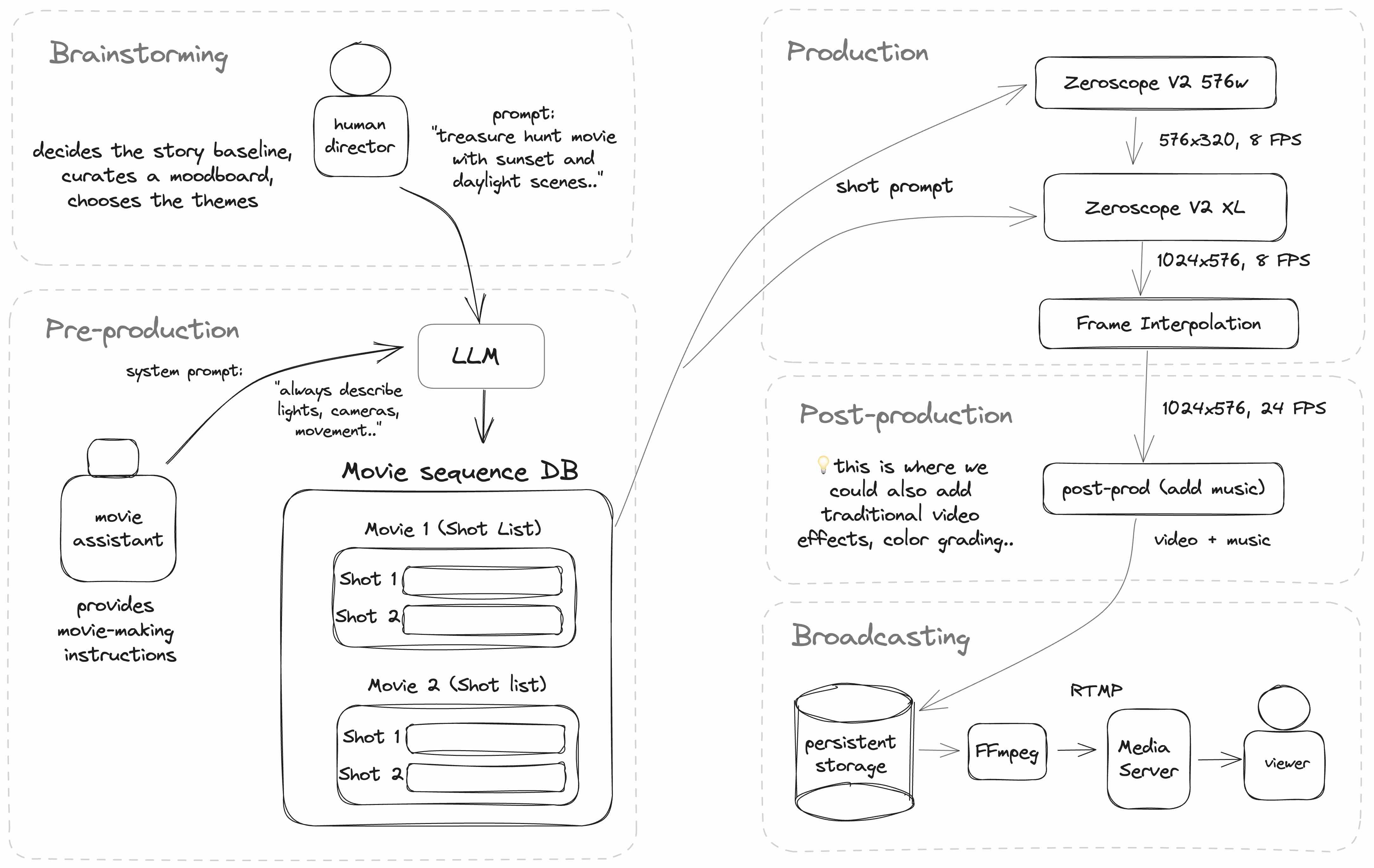
AI新創Hugging Face最近推出一款平臺AI WebTV,可用來測試開源的生成式AI模型表現,像是文字生成影片模型Zeroscope和音樂合成模型MusicGen,使用者也可在Hugging Face Hub中心找到這些開源模型(即zeroscope_v2_576、Zeroscope_v2_XL和musicgen-melody)。
AI WebTV的運作方式是,由人輸入鏡頭提示,比如「生成一個有夕陽和日光的尋寶電影」,接著,該提示會傳送到大型語言模型(目前使用的是ChatGPT),由模型轉化、生成較專業的鏡頭提示,再將這些提示傳送給影片生成模型,來產出一個個鏡頭畫面。影片生成後,系統還會進入post-production階段,來添加音樂或特效。最後,完成品就會呈現給使用者。(詳全文)
Google 音訊合成 SoundStorm
3秒就能合成完美人聲,Google推高效能音檔生成模型
Google日前發表一項音檔合成模型SoundStorm,用2種方法來解決生成冗長音訊Token序列的問題,與現有主流的自回歸模型AudioLM相比,生成速度快了100倍,且只需3秒範本音檔,模型就能快速生成栩栩如生的人聲或音樂等音訊。
進一步來說,大多數音訊生成方法採用自回歸解碼器,會一一產生Token,雖然能保證音訊品質,但運算速度很慢,尤其是處理長序列。而SoundStorm採用的新方法,包含一個為SoundStream神經編碼器(用來生成音訊Token)量身打造的架構,以及根據自家圖像生成模型MaskGIT而改良的解碼方法,用來更有效率處理音訊Token。因為這些改良方法,SoundStorm可以平行生成音訊Token,也因此,SoundStorm推論長序列的速度比AudioLM快上100倍,還能產出相同品質的音檔,其語音和聲學還有更高的一致性。此外,團隊還將SoundStorm與文字轉語音模型SPEAR-TTS結合,能產出更高品質、更自然的對話。(詳全文)
圖片來源/MosaicML、Meta、GitHub、微軟、Hugging Face
AI近期新聞
1. ChatGPT推出可客製化的指令,先供付費用戶試用
2. Meta AI推出ImageBind專案,可整合圖像、聲音、文字、影片、熱、深度和慣性等6種模態來訓練更智慧的AI模型
資料來源:iThome整理,2023年7月
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-12


2026-02-10

2026-02-06