AWS在機器學習服務Amazon SageMaker添加回應串流(Response Streaming)新功能,用戶現在可以將模型推論結果串流傳輸至客戶端,在回應生成時立即開始串流傳輸回應,不必等待回應完全生成,而這將可加速生成式人工智慧應用程式收到第一個位元組的時間。
過去用戶發送查詢,需要等待回應完全生成完畢,才能夠收到答案,是以批次作業的方式進行,但是這可能會需要數秒或是更長的時間,官方提到,這樣的形式降低了應用程式的效能。透過應用回應串流功能,應用程式可以更快地產生回應,在用戶看到初始回應時,人工智慧可以繼續在後臺完成處理其解答,聊天機器可以更迅速發送生成結果,如此便能夠創建無縫地對話流程,讓終端使用者獲得流暢的對話體驗。
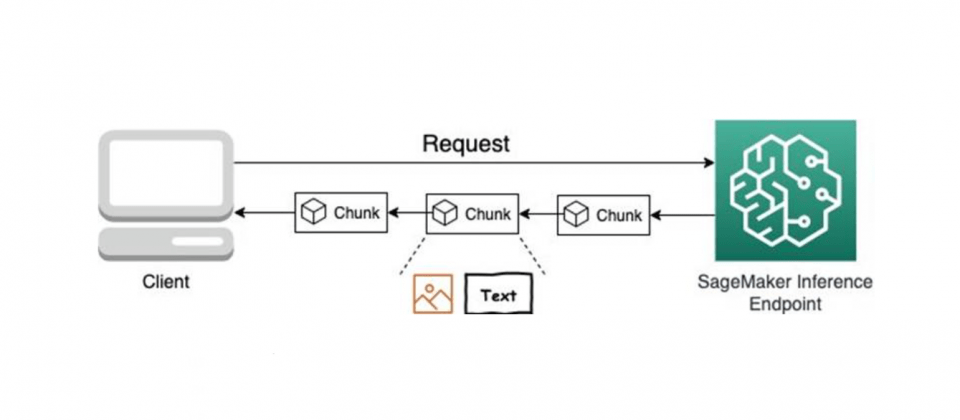
要從SageMaker擷取串流回應,用戶需要使用新的InvokeEndpointWithResponseStream API,應用程式將可以更快地收到第一個回應位元組,使用者會明顯有感覺延遲降低,AWS提到,在人工智慧應用程式中,立即處理的價值比獲得整個完整有效負載更重要,而且更能創建有黏著度的對話,藉由實現互動的連續性創建更好的用戶體驗。
包括文字和圖形形式的結果,都可以運用串流式回應,也就是說在SageMaker端點所託管的Falcon、Llama 2和Stable Diffusion等模型,都能夠將模型推論結果以串流的形式回傳。官方深入解釋,SageMaker即時端點回應串流是透過HTTP 1.1區塊編碼實作而成,也就是説資料會被分成多個區塊(Chunked)傳輸,而非一次性傳送整個資料,伺服器可以在生成內容的同時立刻開始傳輸,不必等待所有內容都準備好。
要使用這項新功能,用戶需要擁有AWS IAM(Identity and Access Management)角色帳戶,並具備管理部分解決方案資源的權限,除了網頁機器學習開發環境Amazon SageMaker Studio,用戶也需要請求相對應SageMaker託管執行個體的服務配額。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10


2026-02-06

2026-02-10