
作為一款致力於成為數位化企業「最強大腦」的服務,Azure Synapse Analytics 高效高彈性的架構設計、簡單易用的操作、強大的功能和澎湃的資料處理和分析能力,能夠説明我們解決與資料準備、資料管理、資料倉庫、大數據和 AI 等方面有關的很多挑戰。
我們將通過《資料“科學家”必讀》系列文章帶領大家全面體驗 Azure Synapse Analytics。本系列共分為六期內容,本篇是其中的第三期:
-
Azure Synapse Analytics 與 Azure Function 服務的配合使用;通過增量資料 CDC 對 Azure Synapse Analytics 中的資料進行更新;
-
借助 Azure Data Factory 工具實現資料處理水線的自動化操作;
-
借助 Synapse Link 的一鍵同步省略 ETL 過程,實現最新資料的直接訪問。
在上一期內容中,我們已經介紹了如何通過 Cosmos DB 的 ChangeFeed 功能將 OLTP 資料向下游的 OLAP 系統快速、高效的增量同步。本期,我們將介紹如何借助 Azure Functions 實現 ChangeFeed 的增量資料抽取邏輯。
Azure Synapse Analytics 與 Azure Function 服務如何搭配使用
首先,回顧一下整個架構:
.jpg)
上一期我們曾經提到,借助 Azure Functions 服務可以簡化整個邏輯的代碼開發,Azure Functions 服務中原生已經內置了很多與 Azure 其他服務原生集成的連接器,可以説明客戶實現與上下游服務的對接,使用者無需關注連接器的實現,通過框架的調用,就可以直接通過物件訪問到上下游服務中的資料,進而只需要關注業務邏輯即可。
Cosmos DB 也在 Azure Functions 的支持之中,並且內置的連接器也是 ChangeFeed 實現的。使用者可以直接開箱即用地實現 ChangeFeed 資料讀取,無需自己維護抽取邏輯代碼。Azure Functions 原生支援的連接器如下:
|
Type |
1.x |
2.x and higher1 |
Trigger |
Input |
Output |
|
✔ |
✔ |
✔ |
✔ |
✔ |
|
|
✔ |
✔ |
✔ |
✔ |
✔ |
|
|
✔ |
✔ |
✔ |
|
✔ |
|
|
✔ |
✔ |
✔ |
|
✔ |
|
|
✔ |
✔ |
✔ |
|
✔ |
|
|
✔ |
✔ |
✔ |
|
✔ |
|
|
|
✔ |
|
✔ |
✔ |
|
|
|
✔ |
|
✔ |
✔ |
|
|
|
✔ |
|
|
✔ |
|
|
|
✔ |
✔ |
✔ |
✔ |
|
|
|
✔ |
|
✔ |
|
|
|
✔ |
|
|
✔ |
✔ |
|
|
✔ |
|
|
|
✔ |
|
|
✔ |
✔ |
✔ |
|
✔ |
|
|
✔ |
✔ |
|
|
✔ |
|
|
✔ |
✔ |
✔ |
|
✔ |
|
|
|
✔ |
|
✔ |
✔ |
|
|
✔ |
✔ |
|
✔ |
✔ |
|
|
✔ |
✔ |
✔ |
|
|
|
|
✔ |
✔ |
|
|
✔ |
接下來,就一起看看該如何通過 Azure Functions 實現 ChangeFeed 的增量資料抽取邏輯。
1、準備開發環境。建議使用 Visual Studio Code,其內置的 Azure Functions 開發擴展可以方便開發。詳情可參考這裡。
2、創建 Azure Functions 項目。注意在選擇 Trigger 部分請選擇 Azure Cosmos DB。詳情可參考這裡。
3、準備 function.json 設定檔。function.json 主要描述 Function 與上下游資料連接的參數,其中下述配置中 type:cosmosDBTrigger 部分定義了 Cosmos 的連接資訊,databaseName 和 collectionName 需要替換為前面創建的 cosmos db 的名稱,leaseCollectionName 是 Functions 用來維護租約和 CheckPoint 所需的。connectionStringSetting 參見後續 local.settings.json。type:blob 部分定義了 Function 下游存儲 Data Lake 的連接資訊,其中 path 參數定義了 Function 抽取增量變化資料在 Data Lake 中的存儲路徑,connection 參數參見後續 local.settings.json。另外 feedPollDelay 參數表示 Functions 服務輪詢 ChangeFeed 資料的間隔,其單位為毫秒,在演示中建議可設置為 60000,實際根據資料水線處理時間和資料更新需求來決定。
.jpg)
4、準備 local.settings.json。該設定檔中定義了在上述 function.json 中所引用的連接金鑰參數,其中 Cosmos_DOCUMENTDB 和 ChangeFeedResultStorage 內分別填入 Cosmos 和 Data Lake 的連接字串,這些資訊可在門戶中對應資源的 Access 資訊部分獲取。
.jpg)
5、準備業務邏輯代碼 init.py。init.py 是 Function 函數被拉起後的 entrypoint 函數,我們將前面介紹的抽取 ChangeFeed 增量變化資料的代碼邏輯定義其中,下述演示代碼中通過調用 documents 和 outputblob,借助 Functions 內置的連接器實現對上下游資料訪問,無需再自己開發集成代碼。使用者只需要開發自己的資料處理邏輯即可,演示中是將增量變化資料轉存到 Data Lake 存儲中。
.jpg)
6、通過 VS Code Functions 本地調試工具進行測試,可以模擬通過前幾期中介紹的資料插入函數在 cosmos db 內插入一些新的資料,然後在 Data Lake 中確認是否轉存成功。詳情可參考這裡。
7、將 Functions 服務打包發佈至 Azure Functions 服務中,上述開發測試均在本地完成,測試無誤後將代碼正式發佈至 Azure Functions 服務。詳情可參考這裡。
至此,通過 Azure Functions 服務完成 ChangeFeed 讀取及轉存至 Data Lake 的操作已經順利完成。整個 Function 代碼中 function.json 中針對不同連接器的參數說明可參閱這裡。
介紹完了今天的第一部分-我們已經介紹了如何通過 Azure Functions 實現 ChangeFeed 的增量資料抽取邏輯,借此完了從上游 Cosmos DB ChangeFeed 抽取資料並轉存至 Azure Data Lake 的操作,各位是否現在學會了 Azure Synapse Analytics 與 Azure Function 服務如何配合使用?接下來,今天的第二部分我們要來介紹如何實現對所有這些 CDC 資料的 ETL 操作,通過增量資料 CDC 對 Azure Synapse Analytics 中的資料進行更新。讓我們繼續看下去。
資料的ETL和更新
我們接下來要介紹如何在 Azure Data Warehouse 中拉入增量資料 CDC(Change Data Capture),並對 Azure Data Warehouse 現有資料進行更新。
還記得這個架構嗎?
.jpg)
在上述架構中,Data Lake 的下一跳是 Data Factory 服務。Data Factory 服務扮演資料水線工具,可以自動完成整個 CDC 資料 ETL 並更新到 Data Warehouse 中。
整個方案中 ETL 和更新都借助 DW 的算力來實現,即 Data Warehouse 的 ELT 架構。首先,我們需要將 CDC Raw 導入到 Data Warehouse,然後在 DW 中進行 Transform 和 Update 操作。本期首先會介紹在 Data Warehouse 中手動觸發 T-SQL 執行實現的方式,下期則會介紹如何將整個過程通過 Data Factory 實現資料處理水線的自動化。
手動觸發 T-SQL 的操作過程如下:
1. 創建 Azure Synapse Analysis 資源。詳情可參考這裡。
2. 創建 Azure Synapse Analysis SQL Pool。詳情可參考這裡。
3. 通過 Azure Synapse Studio 創建 T-SQL Script。詳情可參考這裡。
4. 創建資料表格,創建 DW 表格,並在演示中使用 demotable 命名。
.jpg)
5. 通過 COPY 命令初始化表格資料,替換 datalakestorageaccountname、Filestoragename 和 filename 為前述 Function 轉存的 Data Lake 存儲對應的資訊。
.jpg)
6. 通過 Select 語句查看當前 DW 表格中資料。
.jpg)
7. 通過 Staging Table 載入 CDC 資料並處理更新 DW 表格中資料。
.jpg)
8. 在 Cosmos DB 側類比更改資料條目,在 DW 手工執行上述 T-SQL 腳本,並通過 Select 語句查新 DW 資料是否已經完成更新。
.jpg)
至此,我們已經可以用手工方式在 Data Warehouse ELT + Update 的資料處理流程跑通。
以下將為大家介紹如何通過 Data Factory 工具將整個資料水線自動化。
上述我們已經介紹了如何在 Azure Data Warehouse 中拉入增量資料 CDC(Change Data Capture),並對 Azure Data Warehouse 現有資料進行更新。接下來,我們將介紹如何通過 Data Factory 工具將整個資料水線自動化。
我們將通過 Data Factory 工具將該資料處理水線實現自動化,大體思路是將前面的 Data Warehouse ETL 和 Update 通過存儲過程在 DW 中函數化,然後通過在 Data Factory 中創建資料水線來調起存儲過程,整個水線的觸發可以通過 Data Lake 中新的 CDC 資料產生作為事件觸發條件。
首先,老樣子,我們來回顧一下整個架構:
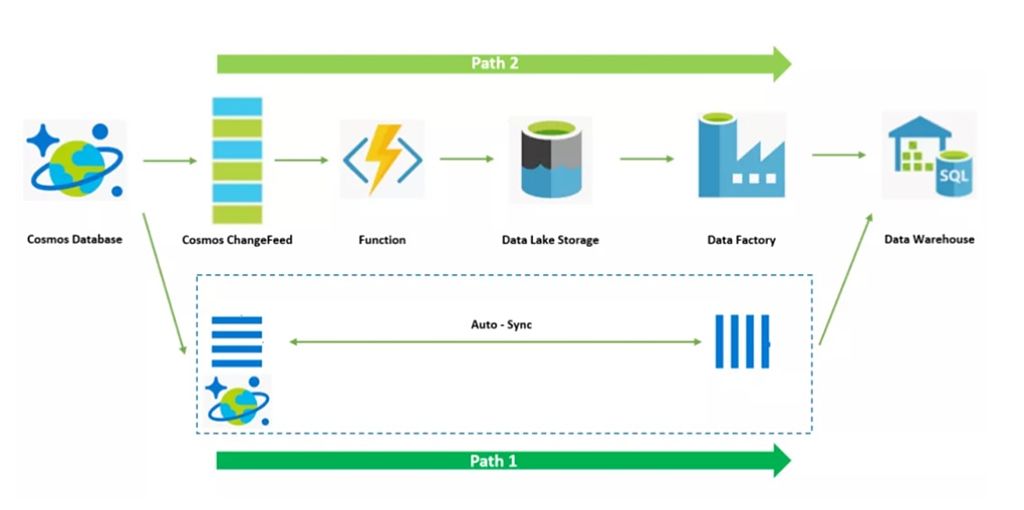
接下來開始介紹具體操作:
1. 創建存儲過程,將上期獲得的 ELT 和 Update T-SQL 腳本通過存儲過程進行實現。

2. 創建 Data Factory Pipeline。先通過 Copy Activity 將 Data Lake 中的 CDC 資料拷貝至 Data Warehouse 中的 Staging Table,再通過調用存儲過程實現對 DW 中生產表格的 Update 操作。此步驟可將下面的 Data Factory Pipeline Json 描述檔導入到 Data Factory 中並按照自己環境中的 SQL Pool 和 Data Lake 連接參數進行修改。

3. 創建 Data Factory Pipeline 觸發條件,定義 Data Lake CDC 檔創建作為觸發條件,其中 blobPathBeginWith 參數和 scope 參數替換為相應 Data Lake 存儲參數值。

4. 通過在 Cosmos 中模擬資料變更操作,查看整個 Pipeline 工作日誌。
通過上述配置,我們實現了通過 Data Factory 資料水線工具自動化完成 CDC 由資料湖導入 Data Warehouse 並更新 Data Warehouse 資料表格的工作。
目前 Azure Synapse Analytics 處於預覽階段,所以在內置的 Data Factory 中還不支持通過 Managed Identity 連接 SQL Pool,且不支持 Blob Event Trigger Pipleline。Managed Identity 問題可使用 ServicePrinciple 來解決,Blob Event Trigger 則會在七月底得到支持,目前大家可通過手動觸發的方式或者使用非 Synapse Analytics 內置 Data Factory 來實現相同邏輯。
到此為止,整個 Cosmos DB ChangeFeed 資料完整的處理流程已經完畢。作為本系列的最後一篇,下期將介紹直通模式 Synapse Link 實現 Cosmos DB 一跳對接 Data Warehouse 的方案。
熱門新聞

2026-02-02

2026-02-03

2026-02-04

2026-02-02

2026-02-04


2026-02-03

2026-02-05