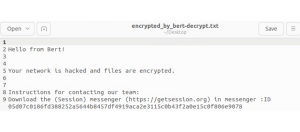
勒索軟體Bert中斷ESXi虛擬機器運作,並啟動50個CPU執行緒快速加密檔案
資安業者趨勢科技指出,勒索軟體駭客組織Bert從5月開始使用Linux版加密程式,主要的攻擊目標是VMware虛擬化平臺ESXi,這個惡意軟體與其他Linux版勒索軟體存在顯著不同的地方,在於能同時占用50個處理器執行緒來加速作業
2025-07-09
針對台積電供應鏈業者萬潤遭駭,勒索軟體駭客組織Bert聲稱從中竊得5 TB內部資料
4月下旬台積電的先進封裝技術供應鏈廠商萬潤發布資安重訊,透露資訊系統遭到攻擊的情況,如今出現新的發展,勒索軟體駭客組織Bert聲稱是他們所為,並場言後續還會公布其他竊得的資料
2025-05-20

和資料工程部資料科學家吳肇中(圖右)指出,Line訊息查證中心成立之初,就採用當時剛問世的NLP經典模型BERT來進行假新聞文章分類和近似文章辨識。")





研究人員利用大量表格資料以及相關的自然語言句子訓練TaBERT,因此TaBERT能夠理解自然語言查詢,並從表格查到答案
2020-07-07
")
新推出的生物醫學文獻探索工具,應用語義搜尋技術良好理解查詢的背後意義,而非僅是進行術語配對
2020-05-06

Google用來解析表格資料的新技術,擴展自BERT模型,可將自然語言問題與表格結構編碼,輸出可計算問題結果的過程
2020-05-04