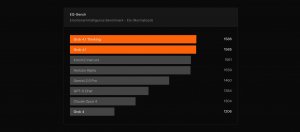
| deno | Deno Deploy | Deno Sandbox | microVM | LLM
JavaScript執行環境Deno沙箱上線,以輕量虛擬機隔離不受信任程式碼
Deno推出Deno Sandbox,讓Deno Deploy以Linux microVM隔離執行不受信任程式碼,並以連外白名單控管連線目的地,搭配sandbox.deploy即可將沙箱程式直接部署到正式環境
2026-02-04

Ollama 17.5萬臺主機曝露,遍及130國,可能面臨LLM濫用風險
SentinelOne與Censys的研究人員發現,開源大語言模型框架Ollama在全球形成約17.5萬臺可公開存取的主機,遍及130個國家,可能成為未受控的AI運算資源池
2026-02-02
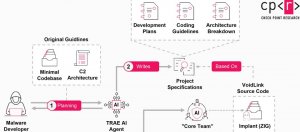
| 惡意軟體 | VoidLink | AI | LLM | LKM | OpSec | Spec-Driven Development
雲端惡意軟體框架VoidLink疑似以AI生成,具開發能力的駭客要求AI根據開發流程,打造近9萬行程式碼的複雜惡意程式
針對一週前揭露的雲端惡意軟體框架VoidLink,資安公司Check Point公布最新調查結果指出,駭客採用AI打造而成,但特別的是,背後竟具備完整的開發流程規畫,開發者負責定義規格、測試,以及整合,程式碼編寫實際上幾乎由AI產生
2026-01-30

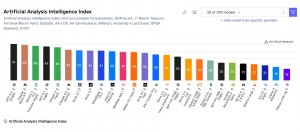
| Artificial Analysis | Intelligence Index | LLM | GDPval-AA | CritPt
Artificial Analysis改版智慧指標v4.0,新增幻覺風險與研究級推理評測
Artificial Analysis更新智慧指標v4.0,移除MMLU-Pro等常見測試,改採GDPval-AA、AA-Omniscience並納入CritPt,讓評測更貼近實務任務與可靠性表現,目前由GPT-5.2(xhigh)暫居榜首
2026-01-10




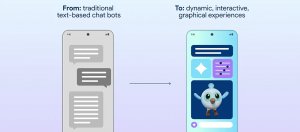
| GenUI SDK | Flutter 生成式UI | LLM
GenUI SDK讓Flutter把對話轉成可操作UI,以LLM動態生成介面
Google測試GenUI SDK for Flutter,讓大語言模型不只回傳文字,也能生成卡片與表單等可操作介面,協助開發者在維持品牌風格下設計更直覺的動態互動
2025-11-20