
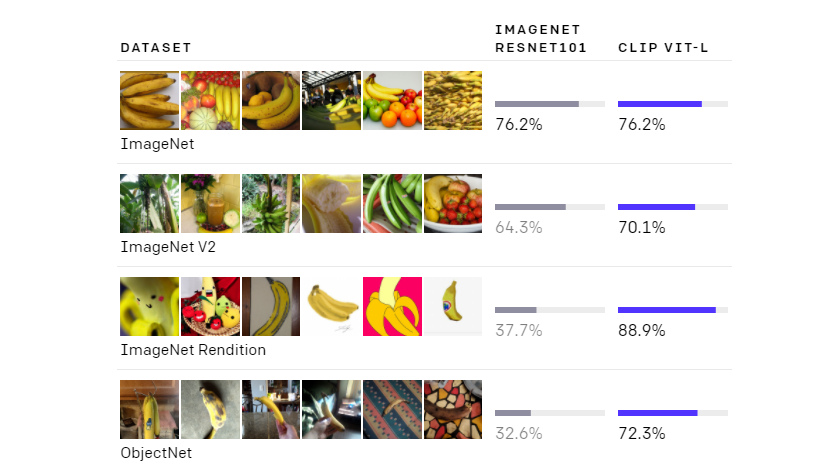
OpenAI以Transformer架構打造自然語言-圖片預訓練模型CLIP,具零樣本學習能力,在一次試驗中,CLIP模型無須以ImageNet中128萬個樣本來優化,就能達到與ResNet50同等的表現,且穩健性差距縮小了75%。
OpenAI
重點新聞(0101~0107)
自然語言 圖像 CLIP
OpenAI發布預訓練模型CLIP,可從自然語言學習視覺概念
OpenAI近日不僅發表超大圖像生成模型DALL·E,也同時發布了一套文字和圖像預訓練模型CLIP,可根據自然語言,來學習視覺概念。OpenAI指出,使用者只要提供圖像類別名稱,就可直接將CLIP應用於任何影像分類的基準測試(Benchmark),無須優化。這點類似於OpenAI先前開發的超大NLP模型GPT-2和GPT-3的零樣本學習能力(Zero-shot learning)。
OpenAI指出,儘管深度學習顛覆了電腦視覺領域,但目前的學習方法仍存在諸多問題,比如,要建立大型電腦視覺資料集,需耗費大量人力,而且這些大型資料集,多半只用於少數特定任務。再來,主流的電腦視覺模型,只對單一項任務有極好的表現,若要讓模型學習新任務,還得花大量時間調校;此外,在基準測試上表現良好的模型,往往在壓力測試上讓人失望。
為克服這些挑戰,OpenAI利用網路上各式各樣的文字和圖片,來訓練類神經網路CLIP,讓模型在文字的監督下,來執行各種電腦視覺分類的基準測試任務。OpenAI指出,CLIP的特點在於,能從未過濾、多樣且高度雜訊的資料中學習,而且CLIP模型比ImageNet的模型還更靈活,在一場試驗中,CLIP模型無須針對基準測試優化,也就是不必利用ImageNet上128萬個樣本來優化,就能達到與經典模型ResNet50相當的表現,且兩者的穩健性差距縮小了75%。(詳全文)
OpenAI DALL·E 圖像生成
GPT-3也有影像生成版!OpenAI的Transformer新作DALL·E靠百億參數準確望文生圖
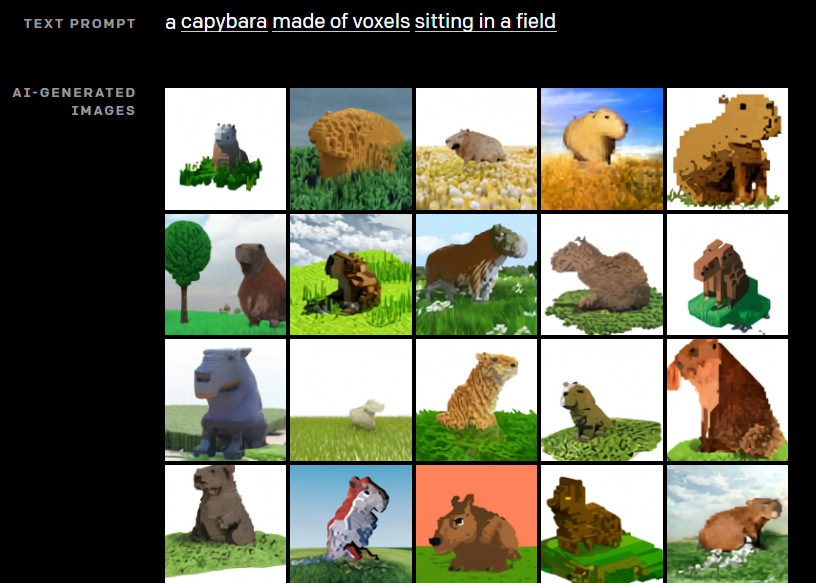
OpenAI近日發表最新影像生成類神經網路DALL·E,擁有120億個參數,可根據文字敘述來產生相對應的圖片。OpenAI在去年6月發表基於Transformer架構的超大自然語言處理(NLP)模型GPT-3,多達1,750億個參數,可根據自然語言輸入值來產生新文本,而今,OpenAI以Transformer打造DALL·E。這個AI模型不只是GPT-3的影像生成版,OpenAI更直言「現已能透過文字來操控視覺概念了。」
DALL·E功能強大,不需額外訓練,就能進行視覺推理(也就是Zero-shot零樣本學習)。它也能控制物件屬性,將文字中不相關的概念,以合理圖像呈現,像是以圖呈現「綠色五角形的時鐘」的敘述;又比如,DALL·E能控制多個物件及其屬性和空間關係,像是準確在圖中呈現「綠色大積木和疊在上面的紅色小方塊」的空間分布,或是「穿著黃褲子、綠上衣,戴紅手套和藍帽子的企鵝寶寶表情符號」。另一個例子則是DALL·E可控制場景視角和渲染場景的3D模式,像是能呈現「由立體像素構成的水豚,坐在田野中」的圖像。不過,OpenAI也表示,模型某些功能的精準度,還有賴於文字敘述的結構。(詳全文)
食藥署 醫材新法 法規鬆綁
5月醫材新法上路,食藥署研擬3指引鬆綁AI智慧醫材軟體上市前驗證流程
衛福部食藥署署長吳秀梅日前在生策會年會上指出,為配合今年5月1日即將上路的醫材新法,食藥署將研訂三項新指引和原則,來簡化智慧醫材產品上市前的驗證流程,甚至符合特定情況者,不需提出申請。
進一步來說,這些指引,包括了對醫療影像AI應用的規範,也就是電腦輔助偵測(CADe)審查要點指引,以及制定原則,來讓特定醫療器材軟體(SaMD)不須向食藥署提出變更申請,最後要定義出不需向食藥署提出申請的無顯著風險(NSR)醫材臨床試驗類別。如此一來,就能加速產業進行臨床試驗的過程。
與此同時,食藥署也準備成立專案辦公室,來協助產業因應將上路的新法,快速推出產品,並推動醫療業與其他產業的跨域整合。(詳全文)

IBM AI工具 雲端運算
IBM國際調查:95%IT主管盼藉AI和自動化工具來改造IT
IBM近日釋出一份針對英國和美國的CIO與CTO大調查報告,310位受訪者中,95%希望藉雲端工具如AI、自動化和資料分析等,來推動企業IT現代化發展。
但報告也指出,雖然雲端運算和數據驅動策略一直是企業討論的熱門話題,但許多大型和中型企業,仍未做好數位轉型準備。因為60%受訪者指出,其IT現代化專案仍不足以因應未來狀況,甚至每4人中,就有1人表示其公司才剛展開IT基礎設施的現代化作業。(詳全文)
Uber AI語音助理 自然語言
Uber讓AI語音助理說話更有禮貌
Uber研究顯示,AI代理使用的社交語言,與使用者的反應和任務完成度息息相關,因此Uber希望打造更有禮貌的對話代理模型,要讓模型使用恰當的社交語言,且兼顧回覆內容。
Uber將研究重點放在客戶服務,可分為兩部分,第一是探討客戶服務代表,以友善言語時所獲得的駕駛回應,還有與第一趟車程的關聯;第二部分以第一部分為基礎,包括23萬多筆資料,來訓練社交語言理解、語言生成元件的語言模型,並由人類評估人員,標記禮貌與正向標籤。Uber總結,改變語言模型輸出訊息的禮貌程度,確實可讓駕駛更快回應,並且遵循最佳作法,包括行為舉止更禮貌,並且使用更正向的語言。(詳全文)
Nvidia 增強學習 模擬環境
Nvidia靠GPU助力,推出增強學習模擬環境Isaac Gym
Nvidia發布增強學習(Reinforcement Learning)研究用的物理模擬環境Isaac Gym預覽版,藉著GPU的平行運算能力,可將過去需要數千個CPU核心參與訓練的任務,移到GPU上,靠單個GPU就能完成訓練。
Isaac Gym採用Nvidia的PhysX GPU加速模擬引擎,不只能更快執行物理模擬,還能讓增強學習的觀察和獎勵運算,得以在GPU上執行,解決運算效能瓶頸,特別是GPU和CPU之間高成本的資料傳輸。Isaac Gym透過實作這兩大功能,提供了完整端到端GPU增強學習工作流程。(詳全文)
攝影/王若樸
圖片來源/OpenAI、Nvidia
AI趨勢近期新聞
1. 不求獎勵的RL代理就更像人類嗎?Google Brain聯手多倫多大學來解答
2. 康乃爾大學打造新模型,可從不同相機視角重建3D人體
3. 自駕車虛擬環境模擬器有新工具了,商湯發表PGDrive來改善自駕代理的通用能力
資料來源:iThome整理,2021年1月
熱門新聞

2026-02-11

2026-02-09
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10