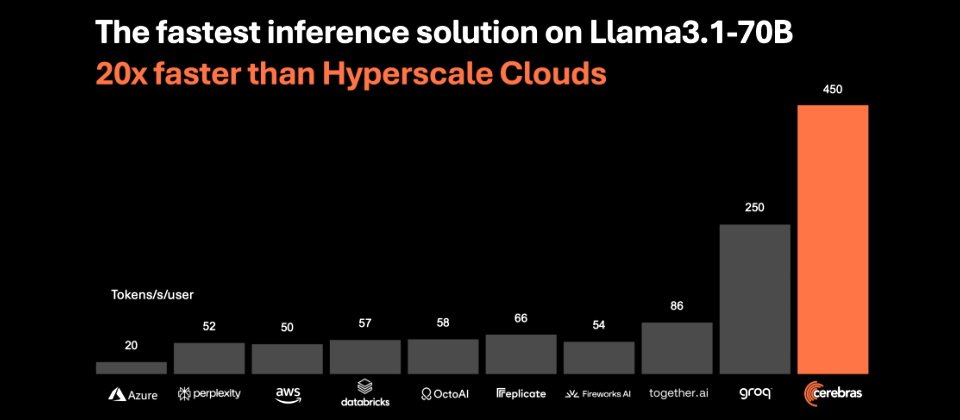
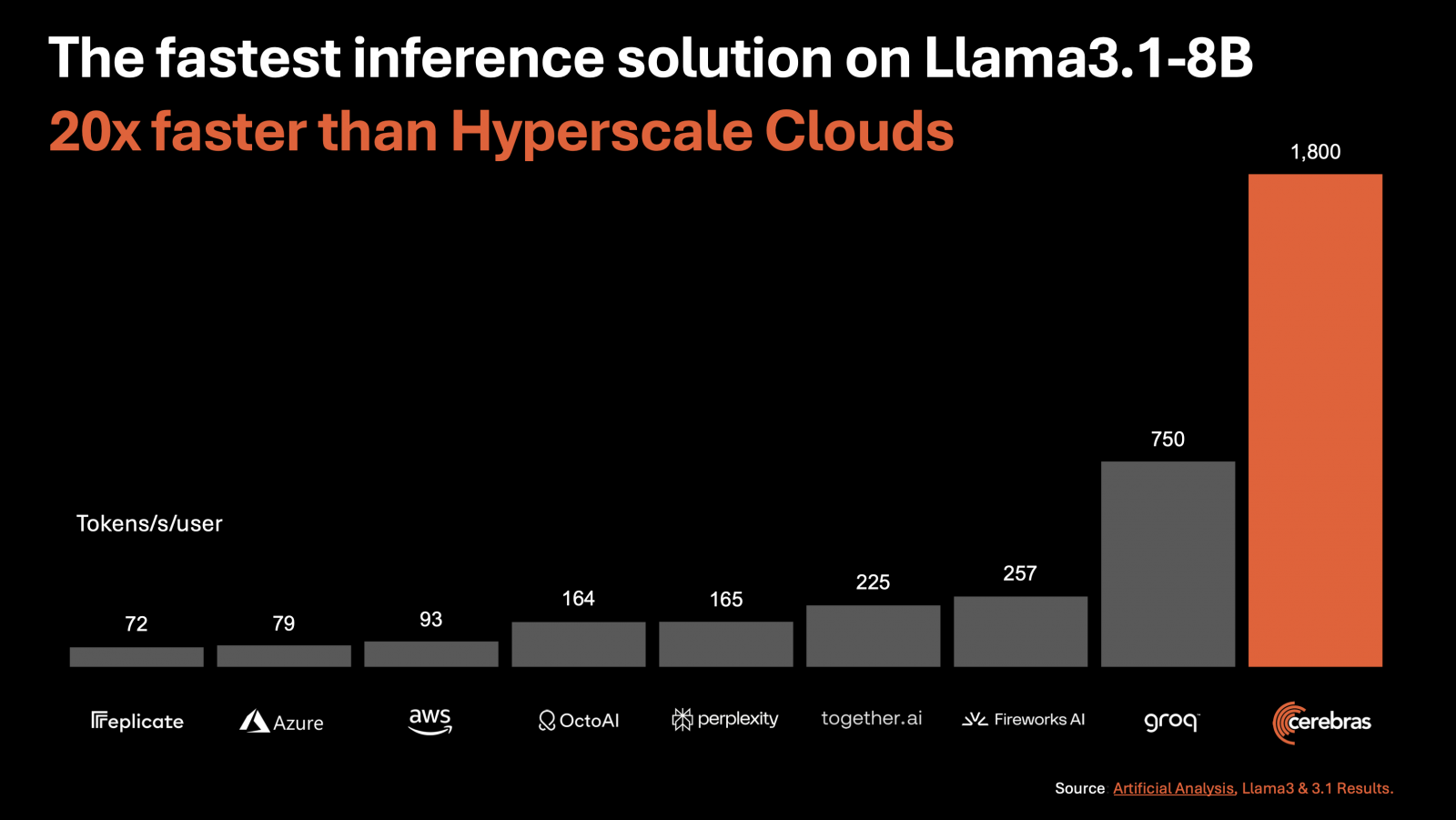
專門開發AI運算系統的Cerebras Systems周二(8/27)發表了AI推論解決方案Cerebras Inference,它在Llama 3.1 8B模型上每秒可生成1,800個Token,在Llama 3.1 70B模型上每秒可生成450個Token,號稱是全球最快的AI推論解決方案,比基於Nvidia GPU的大型雲端解決方案快上20倍,但價格只需1/5,性價比高達100倍。
Cerebras Inference奠基在第三代AI加速系統Cerebras CS-3,該系統的核心為第三代AI晶圓級處理器Wafer Scale Engine 3(WSE-3)。
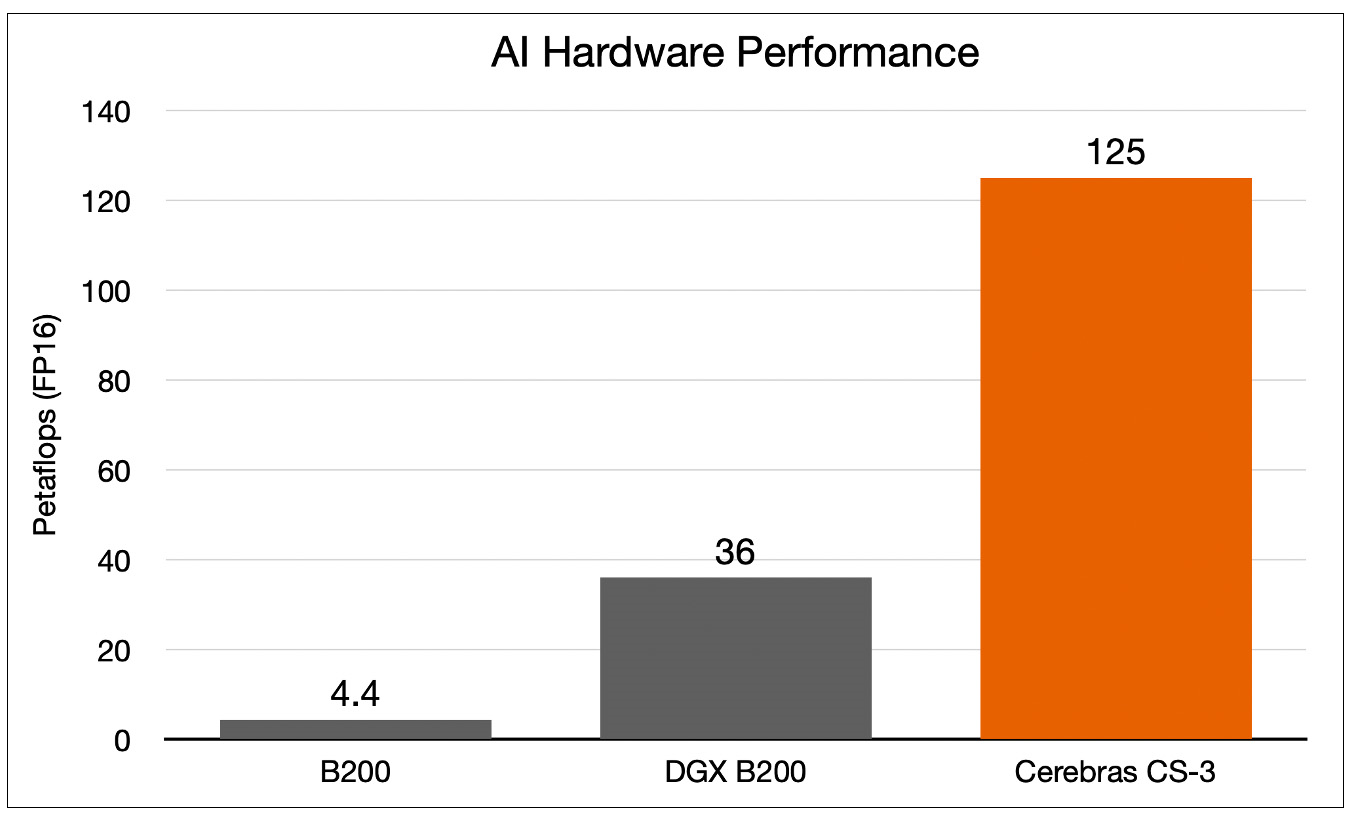
Cerebras曾經比較過WSE-3與Nvidia H100,指出WSE-3的晶片尺寸是H100的57倍,核心數量是H100的52倍,晶片記憶體是H100的800倍,記憶體頻寬更是H100的7,000倍;也曾比較Cerebras CS-3與Nvidia B200,顯示CS-3的表現同樣大幅勝過B200。

目前Cerebras已被視為少數能與Nvidia匹敵的競爭對手,並已計畫於今年下半年首次公開發行股票。
剛上線的Cerebras Inference有免費版、開發者版及企業版,目前其免費版很慷慨地提供了每日10萬次的免費推論;開發者版在Llama 3.1 8B與Llama 3.1 70B模型上每生成100萬個Token的價格分別是0.1美元與0.6美元;而提供微調、客製化服務及專門支援的企業版則可直接聯繫Cerebras以議價。
Cerebras還比較了Cerebras Inference以及各大主要AI雲端服務在基於Llama 3.1 8B模型的性能表現,發現它以每秒生成1,800個Token的速度,遠遠領先Groq的750個、Fireworks AI的257個、together.ai的225個、perplexity的165個、OctoAI的164個、AWS的93個,以及Azure的79個。
提供獨立AI基準測試的Artificial Analysis執行長Micah Hill-Smith指出,Cerebras在AI推論基準測試上領先群倫,它與GPU解決方案根本是不同等級,此外,Cerebras Inference上的Llama 3.1 8B/70B達到與Meta官方一樣的16bit精度成果,對於有即時及高容量要求的AI應用開發者而言特別有吸引力。
此外,推論是AI運算中成長最快的領域,約占整體AI硬體市場的70%。Cerebras形容,每秒可生成上千Token的高速推論,堪比寬頻網路的問世,預告了AI應用的新時代,讓開發人員能夠建置需要複雜、多步驟並即時執行任務的新一代AI應用。圖片來源/Cerebras Systems
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
2026-02-09

2026-02-09
")
