")
生成式AI程式撰寫能力開始媲美真人,AI助手開始能升級老舊程式碼,程式碼優化,自動部署等更多軟體工程領域,IT得成為懂得善用、調度AI的PM

全錄(Xerox)控股公司宣布收購利盟(Lexmark),以切入大型列印市場
2024-12-24
![]()
新聞 | Meta | BLT | Tokenization
Meta BLT語言模型架構突破Tokenization技術極限,推理更快更準
Meta全新BLT架構直接處理位元組資料,取代傳統分詞(Tokenization)技術,其動態分組機制優化資源分配,推理效率較傳統模型提升50%
2024-12-24

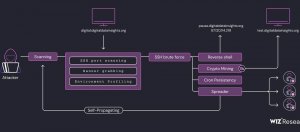
【資安日報】12月23日,羅馬尼亞駭客組織Diicot再度利用Linux主機挖礦
資安業者Wiz揭露羅馬尼亞駭客Diicot(或稱Mexals)近期的攻擊行動,這些駭客專門針對內部網路環境建置的Linux主機而來,企圖將其用來挖礦
2024-12-23
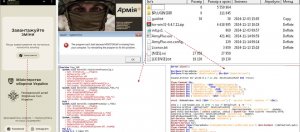

技術長李庭閣表示,中國APT組織在背後政府資金缺乏的情況下,開始商業轉型,轉向攻擊更多缺乏資金和技術的中小企業。")

新聞 | 漏洞揭露 | CVE-2024-12727 | CVE-2024-12728 | CVE-2024-12729 | Sophos Firewall
Sophos修補兩項防火牆重大漏洞,若不處理就有可能遭到SQL注入攻擊、曝露系統特權管理員帳號
上週資安業者Sophos修補3項防火牆漏洞,值得留意的是被列為重大層級的CVE-2024-12727、CVE-2024-12728,影響特定組態的防火牆設備,而有可能成為攻擊者利用的標的
2024-12-23


OpenAI計畫2025年初陸續部署新一代旗艦模型家族o3,先由專門為程式撰寫優化速度的o3 mini打頭陣
2024-12-22

新聞 | Anthropic | AI | Alignment Faking
研究顯示人工智慧模型存在對齊偽裝行為,即表面遵守安全訓練目標,但保留原始偏好,並在特定情境中顯露出來,該現象凸顯現有安全訓練方法的限制,需深入理解機制以確保人工智慧的安全
2024-12-22