
Google表示,被開除的工程師Blake Lemoine宣稱LaMDA模型有感知能力一事毫無根據,在雙方溝通無效、Lemoine依舊選擇違反公司政策情況下,選擇解僱Lemoine
2022-07-25

| Hugging Face | BigScience專案 | 語言模型 | BLOOM | 開源
由AI新創Hugging Face主導並協調的BigScience專案,釋出具備1,760億個參數的大型語言模型BLOOM,其參數規模略勝OpenAI的GPT-3模型
2022-07-14
| YaLM 100B | Yandex | 開源 | 語言模型
Yandex開源具備1,000億個參數的YaLM 100B語言模型
Yandex強調YaLM 100B是全球最大的類生成型已訓練變換模型(GPT)的神經網路
2022-06-24
API(如上圖所示)與Nvidia Megatron-LM中的張量並行提取,所產生的碳足跡只有GPT-3的1/7。(圖片來源/Meta)")
| Meta | Open Pretrained Transformer | OPT-175B | 語言模型
Meta釋出具備1,750億個參數的Open Pretrained Transformer語言模型
OPT-175B語言模型所使用的參數數量,與號稱全球最強大語言模型的OpenAI GPT-3一樣多,不過,Meta強調它們只使用了16個Nvidia的V100 GPU就完成該模型的訓練與部署
2022-05-04


Deepmind利用紅隊語言模型來生成測試使用案例,以自動發現語言模型的各種有害行為
2022-02-08
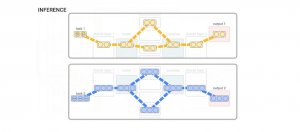
Google讓模型依任務學習路由,有效提高大型語言模型推理效率
Google發表新的新型混合專家模型TaskMoE,大小不只是典型混合專家模型TaskMoE的七分之一,吞吐量更是提升達2倍
2022-01-18

| 吳恩達 | 多模態AI | Transformer | 語言模型 | 達摩院 | 趨勢預測 | IT周報
AI趨勢周報第182期:吳恩達看2022年AI趨勢:多模態AI起飛
吳恩達提出2022年AI趨勢預測,多模態AI將起飛、參數破兆模型會更多、AI生成音檔將成主流;理解力媲美高中生!DeepMind無心插柳柳成蔭,造出超大語言模型Gopher;微軟用Transformer打造通吃多種CV任務的多模態AI,還用來優化Azure認知服務;阿里達摩院發表2022年科技趨勢預測:綠能AI崛起
2021-12-30

Deepmind開發具有2,800億參數的語言模型Gopher,探索模型規模對效能的影響
Deepmind發現增加模型的參數量,並不會全面增加模型的能力,只有特定領域能力大幅增加,且部分領域沒有顯著改善
2021-12-10
")
| 封面故事 | 機器學習 | AI | 日本Yahoo | Line | AI生產力 | HyperCLOVA | 語言模型 | 語料庫
【Line AI生產力關鍵1:通用NLP模型】以HyperCLOVA發展企業NLP服務,下一步搶攻通用AI
Line揭露一款820億個參數的大型語言模型HyperCLOVA,並以此為核心引擎發展一系列企業AI工具,接下來還要結合電腦視覺,打造更通用的AI產品
2021-11-22

Google使用指令微調技術訓練語言模型,使得語言模型能夠懂得遵循指令,並且處理未曾見過的任務
2021-10-07
