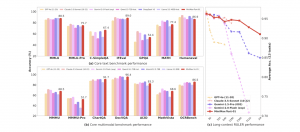
中國AI公司MiniMax推出新LLM,支援400萬Token與多模態應用
中國MiniMax推出MiniMax-01系列,語言模型支援400萬Token上下文處理,性能與頂尖模型相當,多模態模型專注文本與影像結合,適用智慧助理與多媒體生成,定價具競爭力但存政策風險
2025-01-17
| MLCommons | LLM | 安全風險 | 基準測試
MLCommons推出第一個LLM安全基準,促進AI風險評估標準化
MLCommons針對大型語言模型的安全性推出AILuminate基準測試,涵蓋12類潛在危險並進行獨立科學評估,Claude 3.5 Haiku、Claude 3.5 Sonnet、Gemma2 9B、Phi 3.5 MoE Instruct皆達非常好(Very Good)的等級
2024-12-08

| Geekbench AI | 基準測試 | CPU | GPU | NPU | Primate Labs
Primate Labs發表Geekbench AI 1.0
基準測試套件Geekbench AI能夠評測CPU、GPU及NPU處理AI任務的性能,Primate Labs強調在幾分鐘內就能衡量裝置的AI能力,支援TensorFlow、Core ML、ONNX與OpenVINO等主流AI框架
2024-08-16
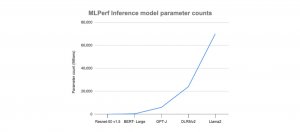
| Nvidia | MLCommons | 基準測試 | MLPerf Inference
Nvidia在Llama 2 70B與Stable Diffusion XL模型基準測試皆拔得頭籌
MLCommons人工智慧模型推理基準測試套件MLPerf Inference v4加入兩個新模型測試,分別是文生圖模型Stable Diffusion XL和開源語言模型Llama 2 70B,而在資料中心分類皆由Nvidia奪冠
2024-03-29
MLCommons成立MLPerf個人端工作組,替個人電腦建立機器學習基準測試
考量個人端裝置執行人工智慧模型需求增加,MLCommons成立MLPerf個人端工作組,創建個人端裝置機器學習基準,衡量系統上人工智慧加速解決方案的效能與效率
2024-01-26

| MLCommons | 基準測試 | 模型訓練 | HPC
開放工程聯盟公開新基準測試結果,AI模型訓練效能5年大幅提升49倍
開放工程聯盟(MLCommons)公布最新的MLPerf Training v3.1與MLPerf HPC v3.0基準測試結果,官方表示,訓練效能基準較5年前提升達49倍,顯示人工智慧技術的大幅進步
2023-11-10

MLCommons成立AIS工作組,推動AI安全基準測試發展
MLCommons成立人工智慧安全工作組,建立一個由多方貢獻的測試平臺,並建立人工智慧安全基準,該平臺將先使用史丹佛大學的HELM框架,針對大型語言模型設立安全基準,對安全性進行評分
2023-10-30

MLCommons發布AI基準測試新套件,強化模型推論和儲存評估
MLCommons推出MLPerf Inference v3.1和MLPerf Storage v0.5基準測試,用於評估人工智慧模型推論和儲存效能,促進技術公平比較
2023-09-12

GRIT電腦視覺基準測試包含7種任務,能夠更全面的評估模型能力,並且鼓勵有效率,非一味追求大資料集的模型學習演算法研究
2022-05-27

Dynabench使用動態基準測試方法,能夠更客觀真實地評估模型的能力,研究人員也能以Dynabench持續更新的資料集,訓練更強大的模型
2020-09-28