
![]()
研究人員透過建立跨地域和職業的性別資料集,提供基準來量測模型的性別偏見,藉此促進偏見相關的機器翻譯研究
2021-06-28
| 臉書 | 機器翻譯 | 資料集 | FLORES-101 | 多語言翻譯 | AI
臉書開源可精確評估多對多翻譯模型的Flores-101資料集
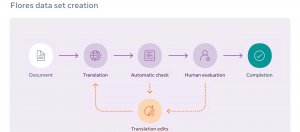
FLORES-101是可用來評估翻譯模型的測試資料集,包含了101種語言的語句,其中有80%為低資源語言
2021-06-07


Google翻譯新模型在100多種語言BLEU分數平均上升5分,50種少資源語言BLEU分數平均上升7分
2020-06-10
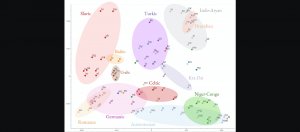
Google以多語言訓練單一神經機器翻譯模型,可同時提升低資源和多資源語言翻譯品質
Google在單一模型訓練多種語言,並不限制每種語言的訓練資料量,可以有效提升低資源語言翻譯品質
2019-10-15

Translatotron模型透過單一的注意力Seq2seq網路,能直接將語音翻譯成另一種語言的語音,中間不需要借助文字資料的轉換
2019-05-16

| google | Google翻譯 | 性別偏見 | 機器翻譯
是「他」還是「她」?Google靠3步驟克服翻譯結果的性別偏見
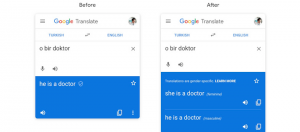
到底是「他」還是「她」?Google最近公開了針對性別翻譯背後的技術,偵測句子中涉及性別的文字,產生不同性別的翻譯結果,再透過準確度評估系統找出最合適的翻譯結果。
2018-12-12
![]()
為了克服缺乏大量翻譯文本的問題,臉書運用非監督式機器翻譯,並利用逐字初始化、語言建模、反向翻譯三步驟改善機器翻譯的效果。
2018-09-04