
| google | TensorStore | 資料集
Google開源專門存放N維資料的可擴展儲存TensorStore
Google所開發的TensorStore,可用於儲存複雜的N維資料集,並且提供簡單的API供機器學習應用存取大型資料集
2022-09-26



Google研究人員收集Reddit上的英文評論,並且移除不適當的言論,對5.8萬條評論以27種情緒分類,製作成目前最大的全註解情緒資料集GoEmotions
2021-11-02

Ego4D資料集由專案參與者,佩戴頭戴式攝影機和各種感測器,拍攝第一人稱視角的影片,教人工智慧透過人眼理解世界
2021-10-15

臉書現在釋出的圖像相似性資料集,是目前已知最大的同類資料集,可用作圖像相似性偵測技術的評估基準
2021-06-22

| google | 資料集 | AI偏見 | Open Images | MIAP | 性別認同 | 多元性別
Google釋出不帶有性別與年齡屬性的人物註解資料集,避免人物辨識模型產生偏見
Google解釋因爲各個資料註解者的文化與背景不同,因此無法產生一致的性別和年齡人物註解,可能在機器模型中出現偏見,因此最新的MIAP資料集,人物皆使用無關性別和年齡的特徵註解。
2021-06-16
| 臉書 | 機器翻譯 | 資料集 | FLORES-101 | 多語言翻譯 | AI
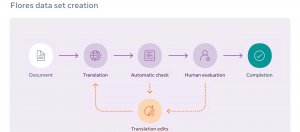
臉書開源可精確評估多對多翻譯模型的Flores-101資料集
FLORES-101是可用來評估翻譯模型的測試資料集,包含了101種語言的語句,其中有80%為低資源語言
2021-06-07

Google公共雲端資料集現在提供更豐富的資料集類型,供企業探索並且可結合私人資料集,獲得深入且獨特的分析結果
2021-05-24

Casual Conversations資料集是由臉書付費召集參與者,所收集而來的人像影片,由參與者自己提供年齡和性別,並且經訓練人員以費氏量表標記參與者的膚色
2021-04-12

CATS4ML要挑戰者從開放圖像資料集中,找出機器學習模型對答案很有把握,但是實際上卻錯誤分類的例子,這些例子可用來避免未來模型可能發生的錯誤
2021-02-16